Начиная с редакции 2020 функция fork() поддерживает вызов в многопоточных процессах. Ранее в этих условиях функция должна была бы вернуть -1 и установить errno в значение ENOSYS. |
Характеристика ядра операционной системы в части принципов управления памятью, пространством путей и имен, а также процессами
Микроядро ЗОСРВ «Нейтрино» и его часть менеджер процессов находятся в едином бинарном модуле – procnto. В общем случае, когда речь идет о ядре операционной системы, имеется в виду именно этот системный процесс. Без него о среде исполнения говорить не приходится.
Менеджер процессов отвечает за создание множества POSIX-совместимых процессов (каждый из которых может содержать множество POSIX-совместимых потоков). Основные функции менеджера процессов:
Пользовательские процессы, как системные, так и прикладные, могут использовать функции микроядра напрямую с помощью системных вызовов или косвенно посредством менеджера процессов через передачу сообщений procnto. Обратим внимание на то, что пользовательский процесс может передать сообщение ядру посредством вызова MsgSend*().
Важно понимать, что собственные потоки процесса procnto обращаются к микроядру с помощью тех же самых механизмов, что и потоки других процессов.
Хотя менеджер процессов и собственно микроядро разделяют одно адресное пространство, это не значит, что у них есть "специальный" или "индивидуальный" интерфейс. Все потоки в системе используют общий интерфейс ядра, и они все выполняют переключение контекстов и системные вызовы штатным образом.
Одной из основных функций procnto является возможность динамического создания новых процессов. Созданные процессы в последствии оказываются зависимыми от других сервисов микроядра, связанных с управлением памятью и пространством имен.
Управление процессами включает в себя как создание, так и уничтожение процессов, а также обслуживание их атрибутов (например, идентификатор процесса, группа процессов, идентификатор пользователя и группы и т.д.).
Существует следующие четыре примитива процессов:
Функция posix_spawn() создает дочерний процесс путем прямого указания подлежащего запуску исполняемого файла. Этот вызов аналогичен функции fork(), за которой следует функция группы exec*(). Однако, вызов posix_spawn() намного более эффективен, так как не требует копирования адресного пространства существующего процесса, как это происходит при предварительном вызове функции fork(), с последующей его перезаписью при последующем вызове exec*().
Одним из главных преимуществ метода совместного применения функций fork() и exec*() является гибкость изменения окружения, которое наследуется дочерним процессом. Это производится в дочернем процессе непосредственно перед выполнением функции exec*(). Например, при выполнении следующей простой shell-команды стандартный поток вывода будет закрыт и повторно открыт до вызова функции exec*():
ls >file
Тоже самое может быть выполнено с помощью функции posix_spawn(). Она предоставляет возможность управлять следующими параметрами наследуемого окружения, которые могут быть скорректированы при создании дочернего процесса:
Существует также аналогичная функция posix_spawnp(), которая не требует указания полного пути к запускаемой программе. Вместо этого она производит поиск исполняемой программы, используя переменную окружения PATH родительского процесса.
Использование функции posix_spawn() является предпочтительным способом создания новых процессов.
Функция spawn() является расширением ЗОСРВ «Нейтрино» и во многом подобна функции posix_spawn(). Она позволяет управлять следующими параметрами дочернего процесса:
Основными формами функции spawn() являются:
Следующий набор функций реализован на основе spawn() и spawnp():
Процесс, порожденный с помощью этих функций, наследует следующие атрибуты родительского процесса:
SPAWN_SETGROUP не установлен в inherit.flags) SPAWN_SETSIGMASK не установлен в inherit.flags) SIG_DFL SIG_IGN (за исключением измененных через inherit.sigdefault, при условии, что параметр SPAWN_SETSIGDEF не установлен в inherit.flags) Атрибуты нового процесса, которые не наследуются от родительского процесса:
SIG_DFL) SIGALRM, устанавливается равным нулю, даже если это не было не так в родительском процессе Если дочерний процесс порожден на удаленном узле, ему не присваивается идентификатор группы процессов и идентификатор сессии (session membership). Такой процесс помещается в новую сессию и группу процессов.
Дочерний процесс может обращаться к унаследованным переменным окружения родительского процесса посредством глобальной переменной environ, описанной в заголовочном файле <unistd.h>.
Для получения дополнительной информации см. описание функции spawn().
Функция fork() создает дочерний процесс, являющийся копией родительского (вызывающего) процесса с дублированием данных вызывающего процесса в дочернем. Большинство ресурсов процесса наследуется. Однако, некоторые из них явно не воспроизводятся в дочернем процессе:
Функция fork() обычно используется для двух целей:
В более ранних ОС, при создании нового потока общие данные помещались в специально создаваемую область разделяемой памяти, которая становилась доступная дочернему и родительскому потоку после выполнения fork(). Такая модель работы с потоками основана на процессах. До появления стандарта POSIX обслуживание потоков могло осуществляться лишь таким способом. С тех пор подобный способ использования fork() было вытеснено POSIX-потками и использованием функции pthread_create().
При создании процесса для выполнения другой программы за вызовом функции fork() обычно сразу же следует вызов функции группы exec*(). Более эффективно это может достигаться с помощью POSIX-функции posix_spawn() или расширения ЗОСРВ «Нейтрино» spawn(). И та и другая совмещают в себе обе эти операции.
Поскольку имеются более эффективные средства создания процессов, чем fork(), ее использование больше всего подходит в тех случаях, когда необходимо обеспечить переносимость существующего кода, а также для написания переносимого кода, предназначенного для UNIX-систем, не поддерживающих POSIX-совместимых функций pthread_create() и posix_spawn().
Начиная с редакции 2020 функция fork() поддерживает вызов в многопоточных процессах. Ранее в этих условиях функция должна была бы вернуть -1 и установить errno в значение ENOSYS. |
Функция vfork() полезна для создания нового контекста с целью последующего вызова одной из функций exec*(). Функция vfork() отличается от fork() тем, что для дочернего процесса не создается копия данных вызывающего процесса. Вместо этого дочерний процесс использует память родительского процесса и его поток управления до тех пор, пока не выполнится вызов одной из функций exec*(). Вызывающий процесс приостанавливается до тех пор, пока дочерний процесс использует его ресурсы.
Дочерний процесс, созданный через vfork(), не может вернуться из функции, вызвавшей vfork(), поскольку в этом случае возвращение управления из родительской функции может привести к обращению к несуществующему фрагменту стека.
Семейство функций exec*() замещает текущий процесс новой программой, загруженной из исполняемого файла. Поскольку вызывающий процесс перестает существовать (замещается), успешное завершение функции не приводит к возвращению значения вызывающему коду.
Существуют следующие функции группы exec*():
Функции группы exec*(), как правило, следуют за функцией fork() или vfork(), с тем чтобы загрузить новый образ дочернего процесса (исполняемый файл). Однако, более эффективным является новый POSIX-совместимый вызов posix_spawn().
Процессы, загружаемые из файловой системы с помощью вызовов exec*() или spawn(), имеют формат ELF (Executable and Linkable Format). Если файловая система реализована на блочном устройстве, программный код и данные загружаются в оперативную память.
Если файловая система уже отображена в памяти (например, ПЗУ или флеш-память), загрузка программного кода в оперативную память не требуется и он может быть исполнен на месте. При таком подходе вся оперативная память может использоваться для сегментов данных и стека, а сегмент кода может оставаться в ПЗУ или флеш-памяти.
В любом случае, если процесс загружается несколько раз, его сегмент код используется всеми совместно.
Некоторые системы реального времени обеспечивают поддержку защиты памяти на уровне среды разработки. Однако, не все они имеют поддержку защиты памяти в среде исполнения, что, как правило, объясняется слишком большими накладными расходами в памяти и производительности. Тем не менее, защита памяти все чаще реализуется во встраиваемых процессорах, так как ее преимущества значительно перевешивают эти потери.
Главное преимущество, которое получает встраиваемая система (особенно система критического назначения), является существенное повышение ее отказоустойчивости.
При наличии защиты памяти, если один из процессов пытается получить доступ к области памяти, которая ему не принадлежит или не была аллоцирована им, блок управления памятью (англ. MMU, Memory Management Unit) может известить об этом ОС, которая в свою очередь может снять данный процесс.
Этим обеспечивается защита адресных пространств процессов, что позволяет предотвратить повреждение памяти потоками в другом процессе и даже в микроядре ОС. Такая защита полезна как в процессе разработки системы, так и при ее функционировании. В том числе это касается возможности изолирования проблем и проведения посмертного анализа процесса, а не всей системы.
На стадии разработки системы, ошибки программного кода (некорректные указатели, выход за границы массива и т.п.) могут приводить к случайной перезаписи данных одним потоком/процессом в пространстве другого. Условием этого является общее адресное пространство для всех процессов. Если такая перезапись затрагивает блок памяти, к которому еще долго не будет производиться обращение, отладка может занять много времени в поисках исходной причины проблемы, далеко отстоящей во времени от точки проявления.
В условиях действующей защиты памяти ОС может завершить сбойный процесс сразу после возникновения ошибки. В пределах одного процесса, однако, этого недостаточно. Но даже и в этом случае проблема оказывается локализованной в его границах, что существенно упрощает отладку.
Типичный MMU делит физическую память на страницы размером в 4 Кб. Процессор использует иерархический набор таблиц страниц, служащих для описания виртуальных адресных пространств процессов, при трансляции обращений из виртуальных адресов в физические.
Во время выполнения потока в таблицы страниц, управляемые операционной системой, позволяют контролировать способ преобразования виртуальных адресов, используемых потоками, в страницы физической памяти и смещения в них.
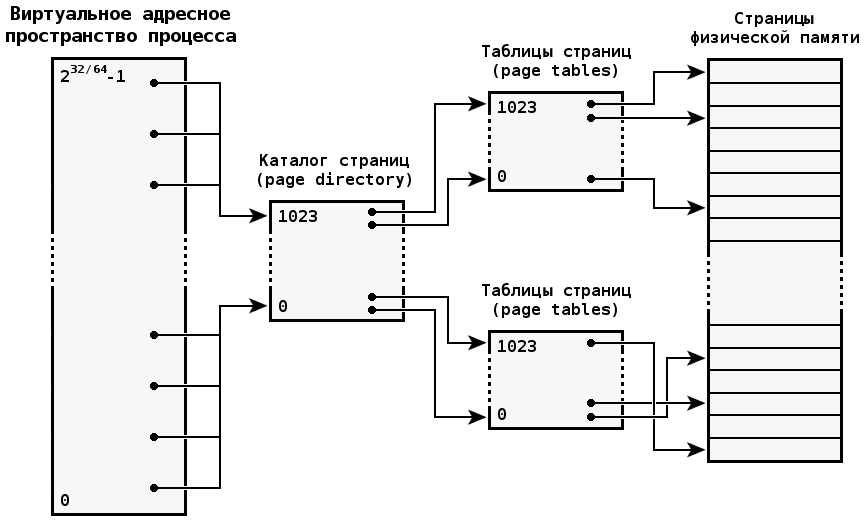
Для большого адресного пространства со множеством процессов и потоков количество записей в таблицах страниц, необходимое для его описания, может быть значительным — больше чем может обслуживать процессор. Для сохранения производительности процессор выполняет кеширование часто используемых сегментов внешних таблиц страниц в буфере ассоциативной трансляции (англ. Translation Lookaside Buffer, TLB).
Обслуживание "промахов" в TLB-кеше — один из видов накладных расходов, связанных с функционированием MMU. Для их снижения в ЗОСРВ «Нейтрино» предусмотрено несколько механизмов обслуживания таблиц страниц.
С таблицами страниц связаны биты, которые определяют атрибуты каждой страницы памяти. Страницы могут быть отмечены как доступные только для чтения, чтения-записи и т.д. К первому типу относятся сегменты кода программ, а ко второму их сегменты данных и стеки потоков.
Когда ЗОСРВ «Нейтрино» осуществляет переключение контекстов потоков – т.е. приостанавливает выполнение одного потока и возобновляет выполнение другого – она требует от MMU использовать для разблокированного потока потенциально иной набор таблиц страниц. Однако, при переключении контекста между потоками одного процесса, манипуляции с контекстом в MMU не требуются.
Когда новый поток возобновляет выполнение, все адреса, сгенерированные в процессе его работы, мапируются в физическую память через назначенную уму таблицу страниц. Если поток пытается обратиться к адресу, который не определен (смапирован) в таблице страниц или использовать адрес с нарушением атрибутов соответствующей страницы (например, запись страницы, доступной только для чтения), процессор сгенерирует аппаратное исключение (ошибка доступа к памяти), которое обслуживается как особый тип прерывания.
Проверяя значение указателя команд (регистр IP или Instruction Pointer), записанное в стек потока при возникновении исключения, микроядро определяет адрес команды, вызвавшей ошибку доступа к памяти, и выполняет необходимые операции.
Защита памяти полезна не только в процессе разработки — она также обеспечивает повышенную степень отказоустойчивости во время работы встраиваемых систем. Во многих системах используются программируемые сторожевые таймеры (watchdog timers), предназначенные для детектирования зависаний. Такой метод менее точен, чем сигнальные устройства на основе MMU.
Аппаратные watchdog таймеры обычно реализуются в виде перезапускаемого таймера с одним устойчивым состоянием, соединенного с линией сброса процессора. Если системное программное обеспечение перестает своевременно передавать ему стробирующий сигнал сброса, то через отведенное время таймер вызовет перезагрузку процессора. Как правило, в системе предусмотрен специальный программный компонент, который периодически проверяет целостность системы и перезапускает watchdog таймер.
Это позволяет восстановить работу системы после зависания из-за программного или аппаратного сбоя, однако он приводит к полной перезагрузке системы и значительным временным издержкам.
В системе с защитой памяти случайная программная ошибка может быть перехвачена ОС и передана заданному пользователем потоку, вместо создания слепка (дампа) памяти проблемного процесса. Этот поток может определить оптимальный способ восстановления работоспособности системы после ошибки, не производя полную ее перезагрузку. Программные сторожевые таймеры позволяют:
Важной особенностью данного подхода является сохранение программного управления системой, даже при сбое в нескольких процессах. Тем не менее, аппаратный watchdog таймер остается полезным для восстановления после аппаратных сбоев, которые невозможно контролировать программно.
В соответствии с реализованной моделью полной защиты памяти весь программный код образа перемещается в новое виртуальное пространство, активируется блок управления памятью и устанавливаются начальные состояния таблиц страниц. Это позволяет запустить procnto в подготовленной среде со включенным MMU. Управление данной средой возлагается на менеджер процессов, который изменяет состояние таблиц в соответствии с запускаемыми процессами.
Изолированные виртуальные адресные пространства
Каждому процессу назначается изолированное виртуальное адресное пространство, которое охватывает от 2 до 3,5 Gb (в системах с 32-битной архитектурой процессора) и более (в системах с 64-битной архитектурой процессора). Точные сведения с привязкой к поддерживаемым архитектурам указаны в разделе Системные требования и лимиты.
На процессорах семейств x86, ARM и MIPS изолированное адресное пространство начинается с адреса 0x0, тогда как на процессорах с архитектурой PowerPC адресное пространство от адреса 0x0 до 0x40000000 (1 Gb) резервируется для системных процессов.
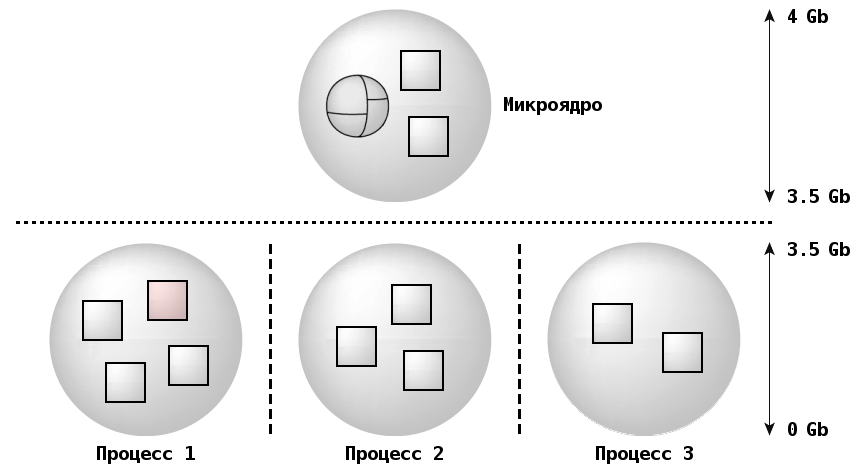
| Накладные расходы, связанные с переключением контекстов потоков и передачей сообщений, возрастают в ответ на повышение сложности адресации между двумя абсолютно изолированными адресными пространствами. Расходы памяти увеличиваются на 4-8 Kb за таблицы страниц каждого процесса. |
Обратите внимание на то, что в этой модели управления памятью есть поддержка POSIX-вызова fork().
Менеджер памяти (компонент микроядра) может использовать изменяемые размеры страниц, если это поддерживается MMU и процессором и несет пользу системе. Использование изменяемого размера страниц благоприятно сказывается на производительности по следующим причинам:
Если необходимо отключить поддержку изменяемого размера страниц, необходимо в файле построения загрузочного образа задать модулю procnto опцию -m˜v. Опция -mv, наоборот, включает поддержку.
ЗОСРВ «Нейтрино» поддерживает блокирование памяти в соответствии с требованиями POSIX. Процесс может избежать потери времени на выборку (fetching) страницы памяти путем ее блокирования – обозначения ее резидентной в памяти (она остается в физической памяти).
Существуют следующие уровни блокирования:
SIGBUS. PROT_WRITE в действительности будут относиться к PROT_READ. Это позволяет ядру при первой попытке записи получить предупреждение о том, что страница MAP_PRIVATE теперь отличается от общего разделяемого хранилища и должна быть приватизирована. PROT_READ). _NTO_TCTL_IO): ThreadCtl( _NTO_TCTL_IO, 0 );
Для осуществления суперблокировки памяти всех процессов необходимо в загрузочном образе задать procnto опцию -mL.
Для всех указанных выше типов памяти при использовании Lazy Mapping (см. флаг MAP_LAZY функции mmap()) страницы физической памяти не выделяются до первых попыток обращения к ним со стороны потока-владельца. Как только к ней обратились, она подчиняется указанным выше правилам — поэтому первичное обращение к области памяти с атрибутом MAP_LAZY из критической секции кода (при выключенных прерываниях или в ISR) является ошибкой программиста.
Большинство пользователей вычислительных систем хорошо знакомы с концепцией фрагментации диска, которая приводит к разбиению свободного пространства на носителе на небольшие беспорядочно-распределенные блоки, чередующиеся с используемыми блоками. Схожая проблема возникает при выделении свободных фрагментов физической памяти, когда со временем физическая память также становится фрагментированной. В результате, может получиться так, что даже при достаточном количестве свободной памяти она будет фрагментирована настолько, что запрос на выделение некоторого объёма физически непрерывной памяти завершится с ошибкой.
Физически непрерывная память обычно требуется драйверам устройств, использующих DMA. Обычным решением является ранний запуск и инициализация всех драйверов устройств (и аллоцирование всей требуемой памяти) – до фрагментации памяти. Это достаточно жесткое решение для встраиваемых систем, для которых единовременный запуск всех требуемых драйверов может оказаться не возможен.
Используемые в ЗОСРВ «Нейтрино» алгоритмы выделения физической памяти способствуют значительному уменьшению объемов фрагментированной памяти. Однако, фрагментация свободной памяти полностью исключена быть не может без строгого отслеживания всеми процессами собственной памяти и контроля ее выделения/освобождения. Что в сложных программах не является тривиальной задачей само по себе. Рассмотрим синтетическое приложение, которое регулярно выделяет 8 Kb физически непрерывной памяти, а затем освобождает половину. Если такое приложение будет исполняться достаточно долго, будет достигнуто такого состояние, когда половина памяти системы свободна, но нет свободных блоков размером больше 4 Kb.
Резюмируя сказанное, можно отметить, что вопрос фрагментации относится не только к алгоритмическим особенностям менеджера памяти, но еще и к логике работы прикладного (внеядерного) кода. Отсюда следует, что потребность в механизмах дефрагментации физической памяти имеется.
Термин «фрагментация» применим как к используемой, так и к свободной памяти:
В дисковых файловых системах фрагментация используемых блоков памяти влияет на производительность операций чтения и записи. Фрагментация же свободных блоков интересна лишь в той мере, что может приводить к фрагментации используемых блоков при их последующем аллоцировании. В иных случаях, когда влияние на производительность отсутствует, о вопросах фрагментации и дефрагментации пользователи предпочитают не задумываться.
Для подсистемы управления памятью ЗОСРВ «Нейтрино» важны оба вида фрагментации, но по различным причинам:
При дефрагментации свободной памяти, менеджер памяти меняет местами используемую и свободную память, таким образом, чтобы блоки свободной памяти укрупнялись и становились достаточными для аллоцирования запрашиваемых непрерывных блоков памяти.
Когда приложение выделяет память, она предоставляется микроядром порциями по 4 Kb, которые выровнены на границе в 4 Kb. Операционная система программирует MMU, что позволяет приложению адресоваться к блоку физической памяти посредством виртуальных адресов. MMU при этом преобразует виртуальный адрес в физический.
Например, при запросе блока памяти в 16 Kb, выделяется четыре страницы по 4 Kb. На уровне MMU выделяется четыре индивидуально непрерывных физических блока (не обязательно представляющих единый непрерывный блок), доступных в приложении в качестве непрерывного виртуально блока адресов. Зафиксируем еще раз - физически эти блоки данных могут не быть смежными, но операционная система может настроить MMU таким образом, чтобы все выделенные страницы физической памяти были доступны в виде последовательных (непрерывных) виртуальных страниц.
Задача дефрагментации состоит в изменении существующих мапирований памяти в приложении для использования других страниц физической памяти. Меняя местами страницы физической памяти, ОС может объединять фрагментированные свободные блоки, укрупняя непрерывные фрагменты. Следует, однако, избегать перемещения некоторых видов памяти, для которых виртульно-физическое мапирование адресов не может быть изменено безопасно:
_NTO_TCTL_IO в описании функции ThreadCtl()) по умолчанию блокирует все принадлежащие ему страницы памяти, т.к. устройства периферии в общем случае оперируют физической памятью, обладающей конкретными характеристиками. Их перемещение может противоречить требованиям оборудования. В тоже время, если оборудование располагает DMA механизмами, оно будет продолжать обращаться по физическим адресам, которые драйверу более не принадлежат, что будет приводить к непредсказуемым сбоям.
Другие случаи, подразумевающие запрет на перемещение памяти перечислены в параграфе Автоматическая маркировка памяти, как неперемещаемой.
При необходимости дефрагментация выполняется, когда приложение выделяет фрагмент непрерывной физической памяти. Приложение может это выполнить посредством вызова mmap(), установив флаги MAP_PHYS | MAP_ANON. В зависимости от того разрешена дефрагментация или запрещена, выделение непрерывной памяти таким способом может привести к:
| Во время дефрагментации поток вызова mmap() блокируется. Операция может занимать длительное время (особенно при выделении больших фрагментов физически непрерывной памяти), но остальные сервисы системы не затрагиваются.
Поскольку остальные системные задачи выполняются параллельно, алгоритм дефрагментации позволяет учитывать, что мапирования памяти могут измениться в процессе его работы. |
По умолчанию, микроядро запускается с разрешенной дефрагментацией. Для запрета дефрагментации необходимо в файле построения загрузочного образа задать модулю procnto опцию -m~d. Опция -md, наоборот, ее включает.
Память, выделенная как физически непрерывная, маркируется микроядром как «неперемещаемая». Это связано с тем, что процессам, которые выделяют память таким образом, важен именно физический адрес блока памяти и его перемещение с большой вероятностью приведет к сбоям.
Кроме того, виртуальная память, для которой был получен физический адрес (при выполнении mem_offset()), также должна быть защищена от перемещения. Однако, операционная система не стремится отмечать всю подобную память как неперемещаемую, поскольку процесс может вызвать mem_offset() «из любопытства» (как, например, профилировщик памяти в IDE). Не во всех таких случаях память защищается от перемещений.
С другой стороны, если приложение рассчитывает на использование результатов работы mem_offset() и ОС переместит выделенную память, это может сломать логику его работу. Такое приложение должно заблокировать используемую память с помощью mlock().
По этой причине procnto предоставляет опцию -ma. При ее установке любые вызовы функции mem_offset() будут маркировать блоки памяти как неперемещаемые. Следует заметить, что на память, аллоцированная как физически непрерывная или блокированная посредством mlock(), уже является неперемещаемой и данная опция на нее не влияет. Опция оказывается значимой только в том случае, если в микроядре не отключена дефрагментация (см. предыдущий параграф).
| Опция -ma по умолчанию отключена. Однако, если обнаружено, что приложение работает некорректно, имеет смысл на время его отладки разрешить автоматическую маркировку памяти неперемещаемой. |
Сервисы ввода/вывода не являются встроенными в микроядро, а реализуются специальными отдельными процессами — менеджерами ресурсов — которые могут динамически запускаться и останавливаться во время работы системы. Менеджер procnto позволяет посредством стандартных программных интерфейсов назначать им в пределах пространства имен свои сферы ответственности. По мере того, как фрагменты пространства путей приобретают собственных владельцев, procnto становится арбитром дерева префиксов (синоним пространства имен) и отслеживает процессы, взаимодействующие с ним. Занятое менеджером ресурсов путевое имя также называют префиксом (поскольку оно может предшествовать именам нижележащих ресурсов, обслуживаемых менеджером). Другое его наименование – точка монтирования (англ. mountpoint), так как именно в этой точке менеджер присоединяется к пространству имен.
Именно такой подход к управлению пространством имен не только позволяет сохранить в ЗОСРВ «Нейтрино» семантику POSIX при реализации доступа к устройствам и файлам, но и сделать наличие конкретных менеджеров ресурсов необязательным в небольших встраиваемых системах. Вышесказанное перекликается с концепцией Unix-подобных операционных систем «всё есть файл» (англ. everything is a file), позволяющей адресоваться к устройствам и сервисам, как к обычным файлам.
При запуске procnto регистрирует в пространстве имен следующие префиксы:
| Префикс микроядра | Описание |
|---|---|
/ | Корневой каталог файловой системы |
/proc/boot | Некоторые файлы из загрузочного образа, представленные в виде упрощенной файловой системы |
/proc/PID | Активные процессы, каждый из которых представлен своим PID (от англ. Process ID). Более подробную информацию см. на странице Программные интерфейсы микроядра. |
/dev/zero | Логическое устройство, которое всегда возвращает ноль. Используется для создания файлов и выделения страниц памяти, заполненных нулями (с помощью функции mmap()) |
/dev/mem | Устройство, которое представляет всю физическую память |
Когда какой-либо процесс открывает файл, POSIX-совместимая библиотечная функция open() отправляет сообщением имя открываемого ресурса менеджеру процессов procnto, который сопоставляет его с содержимым дерева префиксов и определяет какому из зарегистрированных менеджеров ресурсов оно должно быть перенаправлено.
Дерево префиксов может содержать идентичные или частично совпадающие записи (сравнение производится от начала символьной строки), поскольку один и тот же префикс может быть зарегистрирован множеством серверов. Для одинаковых записей может быть задан порядок обхода (см. следующий параграф). Если записи совпадают лишь частично, будет использовано путевое имя с наибольшей совпадающей частью (с наибольшей длиной).
Допустим, что зарегистрированы следующие префиксы:
Здесь, менеджер файловой системы регистрирует префикс для смонтированной (mounted) файловой системы QNX4 – /. Драйвер блочного устройства регистрирует префикс, отображающий весь жесткий диск – /dev/hd0. Менеджеры последовательных интерфейсов регистрируют два префикса для двух последовательных портов.
Таблица ниже демонстрирует, как работает правило "наибольшего совпадения" при разрешении имен.
| Запрашиваемый клиентом ресурс | Соответствующий запросу префикс | Владелец префикса |
|---|---|---|
/dev/ser1 | /dev/ser1 | devc-ser* |
/dev/ser2 | /dev/ser2 | devc-ser* |
/dev/ser | / | fs-qnx4.so |
/dev/ser1/file | / | fs-qnx4.so |
/dev/hd0 | /dev/hd0 | devb-eide.so |
/usr/jhsmith/test | / | fs-qnx4.so |
В большинстве случаев порядок разрешения имен файлов соответствует порядку, в котором были подмонтированы файловые системы в данной точке монтирования (последние примонтированные файловые системы будут размещены перед уже существующими). Порядок обхода может быть определен при монтировании файловой системы. Для этого можно использовать:
Кроме того, при монтировании файловых систем можно использовать опцию -o утилиты mount с ключевыми словами:
Если была установлена опция before, файловая система размещается перед любыми файловыми системами, смонтированными ранее на данной точке монтирования. За исключение тех, которые будут смонтированы с опцией before позже. При установке опции after, файловая система размещается позади любой файловой системы, смонтированной ранее на данной точке монтирования. За исключением тех, которые были подмонтированы ранее с опцией after. Обобщенный порядок поиска объекта в файловых системах имеет вид:
Обход файловых систем в каждом из этих списков производится в порядке их монтирования. Префикс получает первый менеджер ресурсов, запросивший его. Опция after обычно используется в том случае, когда файловая система должна обслуживать объекты, которые никто другой не обрабатывает, а before, чтобы убедиться, что поиск объектов будет производиться в первую очередь в этой файловой системе.
Рассмотрим пример с тремя серверами:
/. Содержит файлы bin/true и bin/false. /bin. Содержит файлы ls и echo. /dev/random. В результате дерево префиксов менеджера процессов выглядит следующим образом:
| Точка монтирования | Владелец префикса |
|---|---|
/ | Сервер A (файловая система QNX4) |
/bin | Сервер B (файловая система флеш-памяти) |
/dev/random | Сервер C (устройство) |
Префикс каждого сервера в действительности эквивалентен совокупности параметров nd, pid, chid для соответствующего канала.
Если клиент собирается отправить сообщение серверу С, то его код может выглядеть следующим образом:
int fd;fd = open( "/dev/random", ... );...read( fd, ... );...close( fd );
В этом случае, системная библиотека выполняет запрос к менеджеру процессов с требованием определить, какой сервер может обработать запрос к пути /dev/random. В ответ на него возвращается список серверов:
Исходя из этой информации, следующим шагом библиотека обращается по очереди к каждому серверу и пытается соединиться с ним, передавая оставшуюся часть пути относительно префикса:
dev/random, так как его точкой монтирования является /. Как только какой-либо сервер подтверждает возможность обработки запроса, обход серверов прекращается. Это значит, что запрос к Серверу А будет направлен только в том случае, если Сервер С не подтвердит соединение.
Данный пример довольно простой – как правило, запросы к точкам монтирования одиночных устройств обрабатывается первым доступным менеджером ресурсов. Особый интерес представляют случаи, когда с точкой монтирования связаны несколько файловых систем.
Рассмотрим пример с двумя серверами из предыдущего параграфа:
/. Содержит файлы bin/true и bin/false. /bin. Содержит файлы ls и echo. Каждый сервер имеет каталог /bin, но их наполнение отличается. После монтирования обоих префиксов произойдет логическое объединение файловых систем, что со стороны пользователя даст следующую картину:
| Точка монтирования | Владелец префикса |
|---|---|
/ | Сервер А (файловая система QNX4) |
/bin | Сервер А (файловая система QNX4) и Сервер B (файловая система флеш-памяти) |
/bin/echo | Сервер B (файловая система флеш-памяти) |
/bin/false | Сервер A (файловая система QNX4) |
/bin/ls | Сервер B (файловая система флеш-памяти) |
/bin/true | Сервер B (файловая система флеш-памяти) |
Разрешение пути /bin происходит так же, как и в предыдущем случае, но процесс не ограничивается возвращением одного идентификатора соединения и все вовлеченные сервера опрашиваются на предмет готовности обработать запрос:
DIR *dirp = NULL;...dirp = opendir( "/bin", ... );...closedir( dirp );
Результатом исполнения этого кода является следующее:
bin в качестве открываемого пути (это часть пути относительно точки монтирования /) Таким образом формируется набор файловых дескрипторов для менеджеров ресурсов, которые обрабатывают путь /bin (в данном случае это два сервера). Имена элементов каталога считываются по очереди при вызове функции readdir(). Если же клиент пытается открыть какой-либо элемент каталога /bin с помощью open(), выполняется обычная процедура разрешения имен путей и запрос направляется лишь одному серверу.
Механизм совмещения точек монтирования очень удобен с точки зрения динамического обновления версий программного обеспечения, обслуживания "на лету" и т.д. Кроме того, этот механизм увеличивает степень интеграции системы, так как префиксы позволяют устанавливать соединения независимо от того, какие службы их предоставляют, что, естественно, дает программный интерфейс более унифицированным.
Менеджер процессов регистрирует в системе префикс, являющийся директорией, который содержит текущий перечень обслуживаемых точек монтирования.
| По умолчанию данный каталог не отображается и при выполнении следующей команды он виден не будет (но просмотреть его содержимое все-таки можно):
# ls -l /proc |
Записи в данном каталоге имеют следующий вид:
# ls -l /proc/mount/ total 18 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,1,1,15,11 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,1,1,16,8 drwxr-xr-x 2 root root 10 Mar 30 11:50 0,1,1,18,0 dr-xr-xr-x 2 root root 0 Mar 30 22:30 0,1,1,3,-1 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,131098,1,0,11 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,155669,4,0,11 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,233494,1,0,11 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,3,1,1,4 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,4,1,0,6 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,4104,4,0,11 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,4107,4,0,11 drwxr-xr-x 13 root root 1024 Mar 30 22:17 0,4107,4,3,0 dr-xr-xr-x 2 root root 1 Mar 30 22:30 0,4108,1,7,11 dr-xr-xr-x 2 root root 1 Mar 30 22:30 dev dr-xr-xr-x 2 root root 1 Mar 30 22:30 net dr-xr-xr-x 2 root root 1 Mar 30 22:30 proc dr-xr-xr-x 2 root root 1 Mar 30 22:30 tmp dr-xr-xr-x 2 root root 1 Mar 30 22:30 usr
Числами здесь являются идентификаторы точки монтирования, перечисленные через запятую:
С помощью этих идентификаторов может быть организован контроль текущих точек монтирования в системе. Так, с помощью команды DCMD_FSYS_MOUNTED_ON можно определить какие файловые системы сейчас смонтированы. Пример такого кода представлен на странице описания команды.
Ранее были рассмотрены префиксы, которые связаны с менеджерами ресурсов. Другим видом префиксов является символьный префикс (symbolic prefix), который представляет собой простую символьную подстановку для указанного префикса.
Символьные префиксы создаются POSIX-командой ln. Эта команда используется для создания жестких или символьных ссылок в файловой системе. Если ей дополнительно к опции -s указать -P, то символьная ссылка будет создана менеджером процессов в дереве префиксов, которое представлено лишь в оперативной памяти.
| Команда | Описание |
|---|---|
| ln -s существующий_файл символьная_ссылка | Создает символьную ссылку в файловой системе |
| ln -Ps существующий_файл символьная_ссылка | Создать символьный префикс в пространстве имен |
| Символьный префикс в пространстве имен всегда имеет приоритет над символьной ссылкой в файловой системе. В тоже время он не является энергонезависимым и будет существовать лишь от загрузки к загрузке. |
Допустим, что имеется машина, в которой нет локальной файловой системы. Однако на другом узле (назовем его neutron) существует файловая система, к которой необходимо получить доступ по имени пути /bin. Это легко достижимо с помощью следующего символьного префикса:
ln -Ps /net/neutron/bin /bin
В результате префикс /bin будет являться отображением пути /net/neutron/bin. Например, имя пути /bin/ls будет преобразовано в /net/neutron/bin/ls.
Это новое имя снова будет сопоставлено с деревом префиксов, но теперь соответствующим запросу префиксом будет /net, указывающий на менеджер ресурсов lsm-qnet.so. Он в свою очередь выполнит разрешение компонента neutron и переадресует последующие запросы на соответствующий узел. На удаленном узле оставшаяся часть имени в запросе (/bin/ls) будет обработана менеджером процессов узла и разрешена в соответствии с удаленным деревом префиксов. В результате этого произойдет отправка запроса менеджеру файловой системы узла neutron. Таким образом, с помощью нескольких простых действий символьный префикс обеспечил доступ к удаленной файловой системе, как если бы она была локальной.
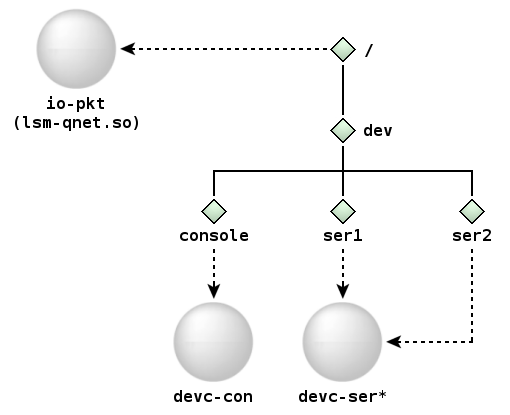
В соответствии с представленной схемой обслуживаемых префиксов, запросы к устройствам /dev/ser1, /dev/ser2 и /dev/console будут обработаны локальными менеджерами символьных устройств, а запросы ко всем остальным ресурсам (файлам и устройствам) будут перенаправлены удаленным сервисам.
Символьные префиксы также можно использовать для создания специальных имен устройств (псевдонимов). Например, если устройство модем доступно под именем /dev/ser1, то для него можно создать символьный префикс /dev/modem:
ln -Ps /dev/ser1 /dev/modem
При любом запросе к устройству /dev/modem произойдет переадресация на /dev/ser1. Такой подход позволяет легко переключить модем на другой последовательный порт посредством простой замены символьного префикса. Это никак не повлияет на работу приложений.
Префиксы необязательно должны начинаться с символа /. В этих случаях путь считается относительным к текущему рабочему каталогу. В ЗОСРВ «Нейтрино» текущий рабочий каталог сохраняется в виде строки символов. Относительные пути всегда преобразуются в полные с учетом сетевого компонента, посредством подстановки в качестве префикса имени текущего рабочего каталога.
Следует отметить, что результат будет отличаться, если текущим рабочим каталогом является /, либо им является сетевой корневой каталог.
В некоторых UNIX-системах, команда cd модифицирует свой аргумент, если этот путь содержит символьные ссылки. В результате, имя нового рабочего каталога (которое можно отобразить с помощью команды pwd) может отличаться от того, которое было изначально передано команде cd.
В ЗОСРВ «Нейтрино» команда cd не модифицирует свой аргумент, за исключением случаев сворачивания ссылок при обнаружении в пути каталога ... Например, при выполнении следующей команды:
cd /usr/home/dan/test/../doc
текущим рабочим каталогом станет /usr/home/dan/doc, даже если некоторые элементы в исходном пути были символьными ссылками.
Более подробную информацию о символьных ссылках и .. можно найти в разделе Файловая система QNX4.
После открытия префикса менеджера ресурсов в действие вступает локальное пространство имен. Функция open() возвращает клиенту целое число, которое представляет собой файловый дескриптор (канал), используемый для перенаправления последующих запросов менеджеру ресурсов.
В отличие от глобального дерева префиксов, пространство имен файловых дескрипторов является локальным для каждого процесса. Менеджер ресурсов использует комбинацию параметров SCOID (от англ. Server COnnection ID, идентификатор серверного соединения) и FD (File Descriptor/connection ID, файловый дескриптор/идентификатор соединения) для детектирования управляющей структуры, связанной с вызовами, следующими за open(). Эта структура называется блоком управления открытым контекстом (Open Control Block, OCB) и является внутренним объектом менеджера ресурсов.
Способ сопоставления пар SCOID и FD с искомым OCB в менеджере ресурсов для активного клиентского соединения изображен на следующей иллюстрации:
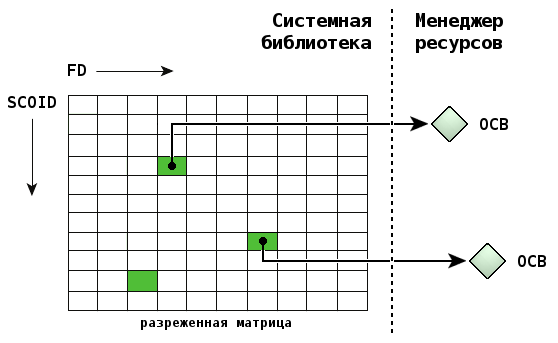
OCB содержит текущую информацию об открытом ресурсе, ассоциированном с сессией пользователя. Например, файловая система может хранить в нем текущую позицию чтения/записи в файле. Каждый успешный вызов open() создает новый OCB на стороне менеджера ресурсов. Поэтому, если процесс открывает некоторый файл дважды, любые вызовы lseek() для одного файлового дескриптора не повлияют на другой. Это же справедливо и для других процессов, открывающими этот файл.
На следующем рисунке показаны два процесса, которые открывают общий файл один или несколько раз. Совместно используемые файловые дескрипторы не применяются.
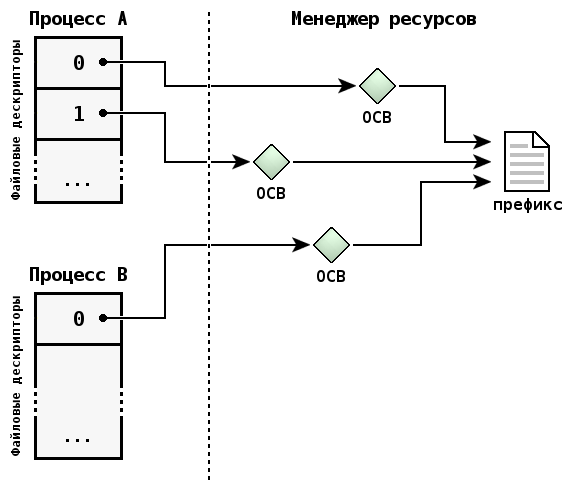
| Владельцем файлового дескриптора является процесс, а не его потоки. |
Несколько файловых дескрипторов процесса могут относиться к одному и тому же OCB. Это достигается следующими способами:
Если несколько файловых дескрипторов относятся к одному OCB, то любое изменение его состояния немедленно становится доступным всем процессам, которые связаны с ним.
Например, если процесс использует функцию lseek() для изменения положения указателя чтения/записи файла, то последующие операции будут происходить уже с новой позиции, независимо от используемого файлового дескриптора.
Следующая диаграмма демонстрирует родительский (A) и дочерний (B) процессы, причем, первый из них дважды открыл префикс, выполнил его дублирование с помощью dup(), а последний унаследовал открытые файловые дескрипторы.
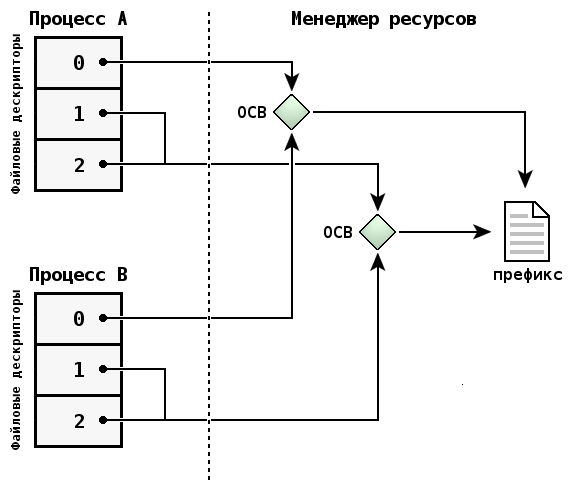
Наследование файловых дескрипторов при вызове функций posix_spawn(), spawn() или exec*() можно запретить. Для этого следует вызвать функцию fcntl() с флагом FD_CLOEXEC.
Предыдущий раздел: перейти