Рисунок 1. Клиент курсирует между состоянием READY и блокировками SEND / REPLY (состояние RUNNING явно не обозначено)
Способы организации междпроцессного (межзадачного) взаимодействия: синхронные и асинхронные сообщения, общая память, сигналы и очереди
Механизм межзадачного взаимодействия (IPC) играет фундаментальную роль в ЗОСРВ «Нейтрино», превращая ее из микроядра реального времени в полнофункциональную POSIX-совместимую операционную систему. IPC действует в качестве связующего звена, соединяющего между собой прикладные процессы, компоненты микроядра и системные службы.
Кроме основной формы межзадачного взаимодействия — обмена сообщениями, в ЗОСРВ «Нейтрино» используются и другие формы. В ряде случаев, другие формы IPC являются надстройками над механизмом обмена сообщениями микроядра. Основная задача состоит в том, чтобы создать простую и надежную систему межзадачного взаимодействия, которую можно оптимизировать по производительности, используя минимум кода в мироядре. На основе существующих примитивов IPC создаются уже более сложные механизмы взаимодействия.
Оценка производительности высокоуровневых механизмов межзадачного взаимодействия (например, неименованные и именованные каналы, реализованные на основе обмена сообщениями) не выявляет существенных отличий от служб с монолитной реализацией.
В ЗОСРВ «Нейтрино» предусмотрены следующие формы межзадачного взаимодействия, сгруппированные по способу реализации:
Разработчики могут сочетать указанные в таблице механизмы в различных комбинациях, в зависимости от требований пропускной способности, необходимости буферизации в очереди, прозрачности передачи по сети и т.д. Поиск компромиссного варианта может быть сложным, но это дает обширную гибкость.
При разработке микроядра ЗОСРВ «Нейтрино» обмен сообщениями в качестве основополагающего примитива IPC избран преднамеренно. Этот механизм реализован посредством функций MsgSend(), MsgReceive() и MsgReply(), является синхронным и подразумевает копирование данных. Рассмотрим подробнее эти две характеристики.
Поток, который выполняет передачу сообщения (посредством функции MsgSend()) другому потоку (который может относиться к другому процессу), блокируется до тех пор, пока поток-получатель не выполнит прием сообщения (см. MsgReceive()) и его обработку, а также не отправит ответ (см. MsgReply()). Если поток вызывает MsgReceive(), он будет заблокирован до тех пор, пока другой поток не выполнит отправку ему сообщения с помощью MsgSend().
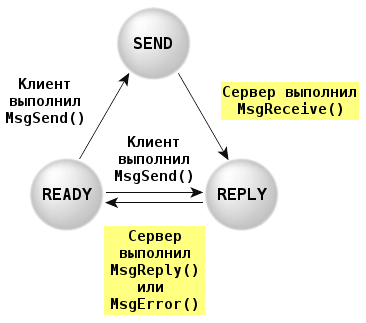
Потоки, которые используют MsgReceive() для ожидания и приема сообщений можно считать серверным. Один или группа потоков, которые с помощью MsgSend() отправляют серверу сообщения, являются его клиентами. Обычно сервер выполняет бесконечный цикл, каждая итерация которого начинается с ожидания сообщения от клиентов. В главе Микроядро: реализация и сервисы были рассмотрены состояния, которые может иметь произвольный поток в системе. Если поток — не важно серверный или клиентский — готов к выполнению на ЦПУ, то ему соответствует состояние READY. Это не эквивалентно потреблению потоком ресурсов ЦПУ,но означает, что поток уже не является заблокированым.
В первую очередь рассмотрим клиентский поток:
Граф переходов включает:
Рассмотрим серверный поток:
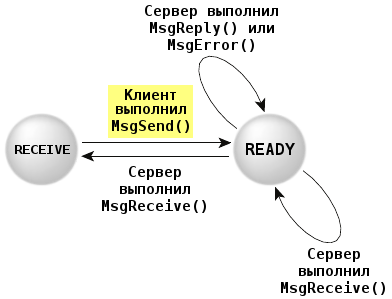
Граф переходов включает:
Такое автоматическое блокирование обеспечивает синхронизацию потоков клиента и сервера. Это не требует от микроядра усилий по определению порядка выполнения потоков, что отличает данный вид IPC от большинства других механизмов. Концепция Send-Receive-Reply (по названию системных вызовов) определяет как очередность выполнения, так и направление передачи данных между контекстами потоков.
Формирование очередей данных при отправке не требуется, поскольку может осуществляться потоком-получателем при необходимости. В общем случае отправитель готов к ожиданию ответа от сервера, но организация очереди является необязательными накладными расходами и замедление работы. В результате потоку-отправителю не нужно делать отдельный явный запрос на блокирование, чтобы дожидаться ответа, как это потребовалось бы при использовании иной формы IPC.
Операции отправки и получения сообщений являются блокирующими и синхронизующими, тогда как вызовы MsgReply() и MsgError() таковыми не являются. Поскольку при отправке сообщения клиент уже заблокирован в ожидании ответа, дополнительная синхронизация ему не требуется. По этой причине функция MsgReply() также не требует блокировки, что позволяет серверу ответить клиенту и продолжить свое выполнение, в то время, как микроядро (или сетевой код) асинхронно передает ответ клиенту и переводит его в состояние READY (готовности к выполнению). Этот механизм достаточно успешен, поскольку большинству серверов необходимо выполнить некоторые действия для подготовки к приему следующего запроса и очередной блокировке.
| Очевидно, передача сообщений в распределенной сети Qnet по своей производительности отличается от локального взаимодействия. |
Функция MsgReply() возвращает клиенту код завершения операции, а также ноль или более байт ответного сообщения. Функция MsgError() возвращает только код завершения и не подразумевает передачу ответа.
Обе функции снимают блокировку клиента, установленную функцией MsgSend().
Поскольку служба обмена сообщениями копирует сообщение из адресного пространства одного потока в адресное пространство другого без промежуточной буферизации, скорость передачи близка к производительности подсистемы памяти на аппаратном уровне. Содержание сообщения для ядра не имеет смысла и не подвергается анализу, оно имеет смысл лишь для отправителя и получателя. Однако, API системной библиотеки предоставляет возможность типизации сообщений, что позволяет прикладному коду возможность дополнять и даже переопределять системные сервисы (определяемые конкретными типами сообщений).
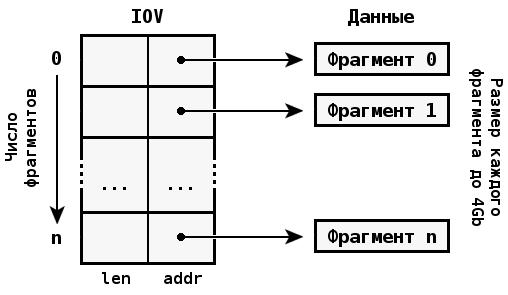
Примитивы обмена сообщениями поддерживают составную передачу данных, поэтому буфер не обязательно должен быть непрерывным в виртуальной памяти. Вместо этого оба потока могут задавать таблицу-вектор, которая определяет на места расположения фрагментов получаемых и отправляемых сообщений.
| Следует иметь в виду, что размер частей сообщения может быть разным для отправителя и получателя. |
Составная передача позволяет пересылать сообщения, в которых заголовок отделен от полезной нагрузки без затрат (копирования) на формирование непрерывного буфера. Кроме того, если исходная структура данных построена на основе кольцевого буфера, формирование фрагментированного сообщения позволяет за одну передачу отправить заголовок и несколько частей, размещенных в кольцевом буфере. Аппаратным аналогом такой схемы передачи данных являются DMA-устройства, поддерживающие фрагментирование/аккумулирование данных.
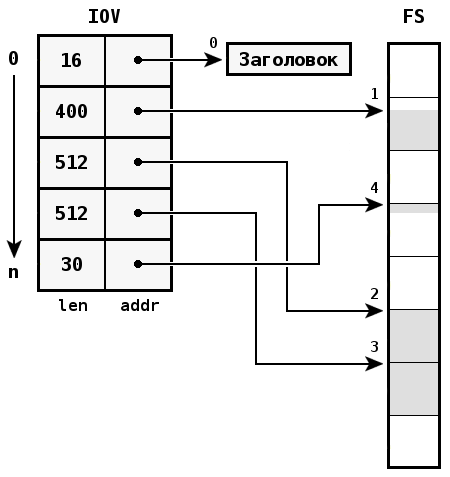
Составная передача часто используется в файловых системах. Из-за фрагментирования данных, при их чтении выполняется копирование из кэша файловой системы в приложение с помощью сообщения, состоящего из n частей. Каждая часть ссылается на кэш, и таким образом решается проблема, связанная с тем, что блоки кэша не располагаются в памяти последовательно, а точка начала или окончания чтения данных может находиться в середине блока.
Например, если размер блока кэша равен 512 байтам, чтение данных размером 1454 байт в худшем случае выполняется посредством передачи 5-фрагментного сообщения.
Поскольку векторное сообщение непрямую копируется из одного адресного пространства в другое, а не мапируется в адресное пространство, данные могут быть размещены в стеке потока. Это позволяет избежать отдельного выделения страниц памяти в MMU. В результате многие библиотечные вызовы IPC могут избежать необходимости манипуляций с памятью.
Например, с помощью следующего кода клиент может сделать запрос к файловой системе для выполнения lseek():
#include <unistd.h>#include <errno.h>#include <sys/iomsg.h>off64_t lseek64( int fd, off64_t offset, int whence ){io_lseek_t msg;off64_t off;msg.i.type = _IO_LSEEK;msg.i.combine_len = sizeof msg.i;msg.i.offset = offset;msg.i.whence = whence;msg.i.zero = 0;if ( MsgSend( fd, &msg.i, sizeof msg.i, &off, sizeof off ) == -1 )return (-1);return off;}off64_t tell64( int fd ){return lseek64( fd, 0, SEEK_CUR );}off_t lseek( int fd, off_t offset, int whence ){return lseek64( fd, offset, whence );}off_t tell( int fd ){return lseek64( fd, 0, SEEK_CUR );}
Данный код строит в стеке структуру сообщения, заполняет ее соответствующими константами и параметрами, переданными от вызывающего потока, и пересылает менеджеру файловой системы, связанному с дескриптором fd. Ответ менеджера сообщает об успешности выполнения операции или возникновении ошибки.
| Поскольку большинство сообщений имеют небольшой размер, ядро выполняет их копирование. Это оказывается гораздо быстрее, чем манипуляции с таблицами страниц на уровне MMU. Однако, для передачи больших сообщений применяется мапирование страниц памяти с формированием разделяемой между процессами памяти. |
Для передачи простых сообщений в ЗОСРВ «Нейтрино» используются функции, которым передается указатель непосредственно на буфер без использования векторов ввода/вывода (IOV, Input/Output Vector). В этом случае количество фрагментов в векторе заменяется на явно заданный размер сообщения. Это создает некоторую вариативность в примитивах передачи/приема сообщений. Варианты функций отправки сообщений:
| Системный вызов | Способ передачи данных | Способ приема данных |
|---|---|---|
| MsgSend() | Указатель на буфер | Указатель на буфер |
| MsgSendsv() | Указатель на буфер | IOV |
| MsgSendvs() | IOV | Указатель на буфер |
| MsgSendv() | IOV | IOV |
В названиях других примитивов, завершающий символ "v" характеризует векторный способ адресации данных:
| Функции с непосредственной адресацией | Векторный вариант |
|---|---|
| MsgReceive() | MsgReceivev() |
| MsgReceivePulse() | MsgReceivePulsev() |
| MsgReply() | MsgReplyv() |
| MsgRead() | MsgReadv() |
| MsgWrite() | MsgWritev() |
В ЗОСРВ «Нейтрино» сообщения передаются с помощью каналов (channel) и соединений (connection), а не напрямую от потока к потоку. Поток сервера для получения сообщений должен создать канал, а потоки клиентских процессов перед отправкой сообщений должен установить соединение с сервером, "подключившись" к этому каналу.
Каналы требуются серверам для приема сообщений с помощью функций семейства MsgReceive(). Соединения создаются клиентскими процессами для "присоединиться" к каналам, открытым серверами. После установки соединения оно может использоваться для передачи сообщений с помощью функций семейства MsgSend(). Если несколько потоков процесса подключается к одному и тому же каналу, то из соображений эффективности все эти соединения на уровне ядра представляют один объект. В пределах процесса каналы и соединения обозначаются целочисленными идентификаторами. Клиентские соединения отождествляются с файловыми дескрипторами.
C точки зрения архитектуры это имеет ключевое значение. Благодаря тому, что клиентские соединения отображаются в качестве файловых дескрипторов, на один уровень абстракции становится меньше. При этом отпадает необходимость "выяснять" на основе файлового дескриптора (например, с помощью вызова read( fd )), куда именно должно быть передано сообщение. Вместо этого сообщение передается непосредственно в дескриптор (который и является идентификатором соединения).
Приведем функции для обслуживания каналов и соединений:
| Функция | Описание | Роль |
|---|---|---|
| ChannelCreate() | Создание канала для получения сообщений | Сервер |
| ChannelDestroy() | Уничтожение канала | Сервер |
| ConnectAttach() | Создание соединения для передачи сообщений | Клиент |
| ConnectDetach() | Закрытие соединения | Клиент |
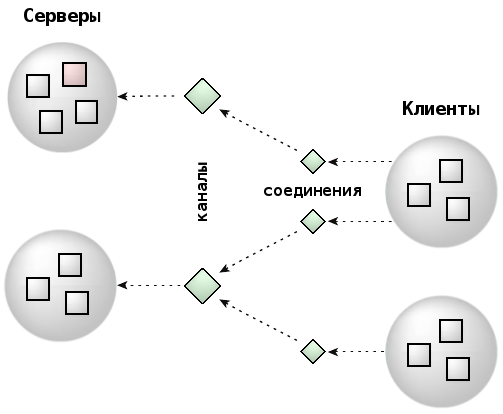
Процесс, выполняемый как сервер, может содержать цикл получения и обработки событий. Пример:
chid = ChannelCreate( flags );SETIOV( &iov, &msg, sizeof( msg ) );for ( ;; ){rcv_id = MsgReceivev( chid, &iov, parts, &info );switch ( msg.type ){/* Обработка сообщения */}MsgReplyv( rcv_id, &iov, rparts );}
Подобный цикл позволяет потоку получать сообщения от любого клиентского потока, установившего соединение с каналом.
| Сервер может использовать функцию name_attach() для сознания канала и ассоциирования с ним символьного имени. Клиентский процесс для создания соединения с таким каналом по его имени может использовать функцию name_open(). |
С каналом ассоциируются несколько списков сообщений:
Находящийся в любой из этих очередей поток блокируется – т.е. имеет одно из перечисленных блокированных состояний: RECEIVE, SEND или REPLY. В каждой очереди может находиться множество потоков (или клиентов).
Кроме синхронного обмена сообщениями, в ЗОСРВ «Нейтрино» используются небольшие неблокирующие сообщения. Такие сообщения называются импульсами (pulses) и имеют размер 4 байта полезной нагрузки и 1 байт с кодом импульса – суммарно 40 бит данных:
Импульсы часто используются в качестве механизма уведомления от обработчиков прерываний, таймеров и т.п. А также позволяют серверам передавать уведомления клиентам не блокируясь.
Сервер получает сообщения и импульсы в порядке приоритетов. После получения запроса потоки сервера наследуют приоритет потока-отправителя (но не его алгоритм планирования). В результате относительные приоритеты потоков, осуществляющих запрос к серверу, сохраняются прежними, а сервер работает приоритетом клиентского потока. Таким образом, механизм наследования приоритетов на основе передачи сообщений позволяет избежать проблемы инверсии приоритетов.
В качестве примера рассмотрим систему, содержащую следующие потоки:
Без механизма наследования приоритетов, при отправке сообщения потоком T2, сервер будет обрабатывать его с приоритетом 22. В результате приоритет потока T2 неявно будет повышен (инвертирован) с уровня 10 до 22.
На самом деле при получении сообщения приоритет потока сервера изменяется на значение максимальный приоритет среди всех заблокированных потоков отправителей. В рассмотренном случае при получении сервером сообщения от клиента T2 эффективный приоритет сервера изменится в момент получения сообщения (при разблокировании серверного потока на вызове MsgReceive()).
Следующим шагом допустим, что T1 отправляет сообщение серверу, пока он все еще имеет приоритет 10. Поскольку приоритет T1 выше текущего приоритета сервера, изменение приоритета сервера происходит, когда T1 отправляет сообщение. Изменение происходит до того, как сервер фактически получит это сообщение, что позволит избежать еще одной инверсии приоритета (когда работы для T1 блокируют запрос от потока T2). Если бы приоритет сервера остался неизменным (на уровне 10) и был бы порожден другой поток (T3) с приоритетом 11 - это привело бы к вытеснению сервера. В этом случае сервер вынужден был бы ждать, пока заблокируется T3, в то время, как он мог бы обрабатывать сообщение от потока T1. Таким образом, инверсия приоритетов характеризуется тем обстоятельством, что поток T3 мешает потоку с более высоким приоритетом – T1.
Если во время обработки запроса от T1, потоком T2 будет послано сообщение, то приоритет сервера не изменится, поскольку приоритет потока T2 будет ниже текущего эффективного приоритета сервера.
Наследование приоритетов можно отключить, указав флаг _NTO_CHF_FIXED_PRIORITY при вызове ChannelCreate(). При использовании адаптивного квотирования этот флаг так же запретит потоку, получающему сообщение, выполняться в партиции (квоте) потока-отправителя.
API системной библиотеки, связанное с механизмом обмена сообщениями, состоит из следующих функций:
| Функция | Описание |
|---|---|
| MsgSend() | Отправка синхронного сообщения и блокировка потока-отправителя до получения ответа от сервера |
| MsgReceive() | Ожидание клиентских сообщений (синхронных или асинхронных) |
| MsgReceivePulse() | Ожидание асинхронных сообщений (импульсов) |
| MsgReply() | Отправка ответа на синхронное сообщение |
| MsgError() | Отправка в качестве ответа кода ошибки (только статус, без полезной нагрузки) |
| MsgRead() | Чтение данных из клиентского буфера (например, если сообщение не поместилось в receive-буфер) |
| MsgWrite() | Запись данных в клиентский буфер (например, если необходимо записать сообщение частями) |
| MsgInfo() | Получение информации о полученном сообщении |
| MsgSendPulse() | Отправка асинхронного неблокирующего сообщения (импульса) |
| MsgDeliverEvent() | Отправка события клиенту |
| MsgKeyData() | Снабдить сообщение ключом безопасности для последующих проверок |
Системный вызов MsgDeliverEvent() предназначен для передачи событий от имени микроядра. Произвольные асинхронные службы могут реализовываться с использованием этой функции. Так, например, серверная часть вызова select() представляет собой программный интерфейс, с помощью которого приложение может заставить поток ожидать завершения операции ввода/вывода на наборе файловых дескрипторов.
Проектирование приложений в виде набора потоков и процессов, взаимодействующих посредством механизма SRR (Send / Receive / Reply) приводит к созданию системы, использующей синхронные уведомления. Межзадачное взаимодействие (IPC) в таких системах осуществляется при определенных транзакциях, а не асинхронно.
Одна из главных проблем асинхронных систем заключается в том, что для получения уведомлений о событиях требуется отдельный запуск специального обработчика. Асинхронное межзадачное взаимодействие может затруднить тщательное тестирование функционирования системы и не дать гарантии, что при вызове асинхронного обработчика работа продолжится ожидаемым образом.
При строго синхронной методике обмена сообщениями (без очередей), построенной на основе SRR, приложения могут иметь одновременно надежную и простую архитектуру.
Взаимная блокировка (англ. deadlock) является еще одной существенной проблемой в приложениях, использующих одновременно несколько различных примитивов IPC: механизмов организации очередей, разделяемой памяти и произвольных примитивов синхронизации. Например, поток A удерживает мьютекс 1 до тех пор, пока поток B не освободит мьютекс 2. Если при этом поток B не может освободить мьютекс 2 до того, как поток A освободит мьютекс 1, возникает тупиковая ситуация, приводящая ко взаимному блокированию на мьютексах друг друга. Для выявления и исправления таких ситуаций часто прибегают к использованию инструментов анализа и моделирования.
| Рассмотренный сценарий возникновения взаимной блокировки не является единственным. Так, например, если разделяемым мьютексом владеет поток только что завершившегося процесса, то остальные заблокированные потоки не смогут разблокироваться без внешней помощи. |
Примитивы SRR позволяют создавать системы, в которых ситуации взаимной блокировки исключены. Для этого достаточно соблюдения следующих правил:
Первое правило направлено на исключение тупиковых сценариев. А вот второе правило требует пояснений:
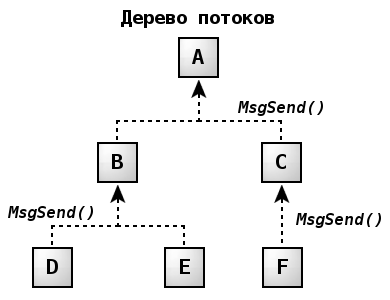
Из диаграммы видно, что на любом уровне иерархии потоки могут пересылать сообщения только наверх, на более высокий уровень. Примером может служить клиентское приложение, передающее сообщение серверу базы данных, который в свою очередь передает сообщение менеджеру файловой системы. Поскольку поток-отправитель блокируется в ожидании ответа, а получатель не блокируется на ответной передаче, ситуация взаимной блокировки становится невозможной.
Но каким образом вышестоящий поток может уведомить клиентский поток о том, что имеются результаты выполнения запрошенной операции? Например, если нижестоящий поток заблокирован в ожидании получения результатов.
Системная библиотека предусматривает системный вызов MsgDeliverEvent(), предназначенный для передачи неблокирующих событий. Произвольные асинхронные службы могут быть реализованы с использованием этой функции. Например, серверная часть вызова select() представляет собой программный интерфейс, с помощью которого приложение может заставить поток ожидать завершения операций ввода/вывода на нескольких файловых дескрипторах. Кроме асинхронного механизма уведомления, который может использоваться для передачи сообщений нижестоящим потокам, можно построить надежную систему уведомлений с помощью таймеров, уведомлений об аппаратных прерываниях и других событийно-управляемых механизмов.
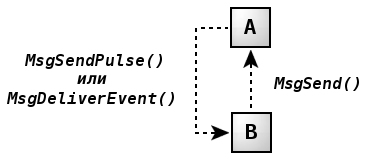
Другая проблема касается того, каким образом вышестоящий поток может запросить у нижестоящего выполнение некоторой работы без передачи ему синхронного сообщения. В данном сценарии нижестоящий поток служит лишь в качестве исполнителя запрошенной работы и передает сообщение вышестоящему потоку для уведомления о готовности к выполнению. Вышестоящий поток не получит это сообщение (и, соответственно, не ответит на него) до тех пор, пока не потребуется отправить задание исполнителю. В своем ответе (передача которого для сервера не является блокирующей операцией) будут содержаться данные, описывающие задачу для клиента. Таким образом, именно ответ служит инициатором работы, а не передача исходного сообщения клиентом. В результате такого подхода обеспечивается соблюдение вышеописанного первого правила.
Стандарты POSIX и их расширения реального времени определяют несколько асинхронных методов уведомления — например, UNIX-сигналы (не выстраиваются в очередь и не пересылают данные) и POSIX-сигналы реального времени (позволяют пересылать данные и буферизироваться в очереди). Кроме того, procnto содержит встроенный механизм отправки уведомлений — импульсы.
Реализация всех этих механизмов в микроядре построена вокруг единой системы передачи событий. Преимуществом такого подхода является то, что возможности одних механизмов уведомления распространяются на остальные. Так, например, может использоваться общая очередь для сигналов разных видов, что существенно упрощает реализацию их обработчиков в приложениях.
Существует три источника событий для исполняемого потока:
События являются контейнером для одного из следующих типов уведомлений: импульсы, уведомления о прерываниях, различные виды сигналов, запросы на разблокировку. Последний вид является средством срочного разблокирования потока со стороны сервера без явно инициированной пользователем отправки события.
Из-за разнообразия типов событий и необходимости приложениям выбирать наиболее подходящий подход к получению уведомлений, нерационально ожидать реализации всех механизмов в отдельно взятом сервере (в высокоуровневом процессе в терминологии предыдущего параграфа).
Вместо этого клиентский поток может передать серверу структуру данных struct sigevent, которая будет описывать ожидаемое от него в последующем событие. Когда серверу потребуется послать уведомление, с помощью вызова MsgDeliverEvent() он потребует от микроядра установить ожидаемый тип события и передать его клиенту.
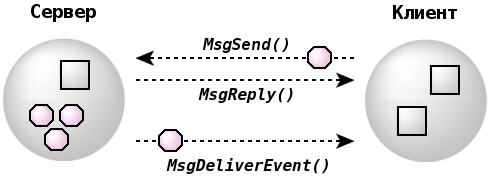
Функция ionotify() — средство, с помощью которого клиентский поток может запросить асинхронную доставку события. На основе этой функции реализуются многие асинхронные службы POSIX (например, mq_notify() и клиентская составляющая функции select()). При выполнении операций ввода/вывода с файловым дескриптором fd клиентский поток может запросить доставку события по завершении процесса (для функции write()) или по факту приема данных (для функции read()).
Вместо блокировки потока на процессе менеджера ресурсов, обслуживающем запрос, функция ionotify() позволяет клиенту сообщить серверу о том, какое именно событие он хотел бы получить при возникновении ожидаемых условий ввода/вывода. Такое ожидание позволяет потоку реагировать на несколько источников событий одновременно, продолжая при этом свое выполнение. Например, это позволяет получать уведомления от файловых дескрипторов нескольких отличающихся менеджеров ресурсов.
Вызов select() реализуется с помощью именно этого механизма и позволяет потоку блокироваться в ожидании событий ввода/вывода от множества файловых дескрипторов, сохраняя возможность реагировать на другие формы межзадачного взаимодействия.
Список условий, при которых может быть доставлено запрошенное событие:
ЗОСРВ «Нейтрино» поддерживает как 32 стандартных сигнала стандарта POSIX (аналогичные UNIX-сигналам), так и сигналы реального времени стандарта POSIX. Нумерация обоих наборов сигналов в микроядре реализована сквозным образом – на основе набора из 64 сигналов с унифицированной функциональностью. Хотя POSIX-сигналы реального времени в стандарте отличаются от UNIX-сигналов (первые могут содержать 4 байта данных и 1 байт кода и накапливаться в очереди на доставку) их фактическая функциональность может быть опционально включена или отключена для каждого конкретного сигнала, что позволяет всей реализации соответствовать стандарту.
По запросу приложения UNIX-сигналы могут использовать механизмы буферизации в очереди сигналов реального времени. Кроме того, ЗОСРВ «Нейтрино» расширяет механизмы доставки POSIX-сигналов, позволяя отправлять сигналы как отдельным потокам, так и всему процессу (первому подходящему по маске потоку в нем). Поскольку сигналы — это асинхронный примитив IPC, они могут использоваться в механизме передачи событий (см. параграф События).
| Системный вызов | POSIX-вызов | Описание |
|---|---|---|
| SignalKill() | kill(), pthread_kill(), raise(), sigqueue() | Отправить сигнал на группе процессов, процессу или потоку |
| SignalAction() | sigaction() | Определить действие, выполняемое при получении сигнала |
| SignalProcmask() | sigprocmask(), pthread_sigmask() | Изменить маску заблокированных сигналов потока |
| SignalSuspend() | sigsuspend(), pause() | Блокировка до поступления сигнала и вызова его обработчика |
| SignalWaitinfo() | sigwaitinfo() | Ожидание сигнала и возвращение информации о нем |
Для многопоточных процессов устанавливаются определенные правила (POSIX регламентировал лишь правила обработки сигналов процессом):
Когда сигнал доставляется многопоточному процессу, микроядро выполнит сканирование таблицы потоков для поиска первого, у которого данный сигнал не замаскирован. Для большинства таких процессов стандартной практикой является маскирование каждого конкретного сигнала во всех потоках за исключением одного, который должен будет его обработать. Для повышения эффективности доставки сигналов процессам, ядро выполняет запоминание последнего потока, принявшего некоторый сигнал, и впоследствии он будет в приоритетном порядке получать данный сигнал.
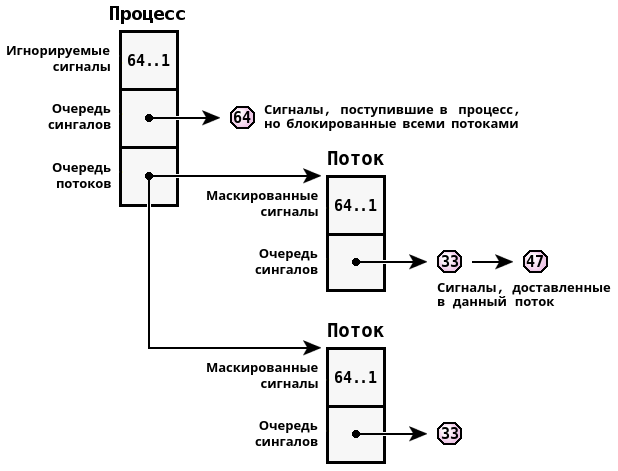
Стандарт POSIX подразумевает постановку в очередь лишь сигналов реального времени. В ЗОСРВ «Нейтрино» это применимо к любым сигналам. Разрешение постановки сигналов в очередь определяется для каждого сигнала отдельно. С каждым из них также может быть связан 8 битный код и 32-битное значение.
В этом отношении сигналы очень похожи на импульсы, описанные ранее. В ядре это сходство используется для задач оптимизации, используя общий код для управления сигналами и импульсами. Номер сигнала преобразуется в приоритет импульса с помощью выражения _SIGMAX - signo. Таким образом, сигналы доставляются в порядке своих приоритетов, причем, чем меньше номер сигнала, тем выше оказывается его приоритет. Это вполне соответствует стандарту POSIX, который утверждает, что классические сигналы имеют более высокий приоритет, чем новые сигналы реального времени.
| Использование операций с плавающей точкой в обработчиках сигналов не разрешается. |
Как было сказано ранее, в IPC определено 64 сигнала, которые распределяются в следующих диапазонах:
| Диапазон | Описание |
|---|---|
| 1 … 57 | 57 сигналов стандарта POSIX (включая традиционные UNIX-сигналы) |
| 41 … 56 | 16 сигналов реального времени стандарта POSIX (от SIGRTMIN до SIGRTMAX) |
| 57 … 64 | 8 специальных сигналов ЗОСРВ «Нейтрино» |
Восемь специальных сигналов не могут быть проигнорированы или перехвачены. Попытка вызвать функцию signal() или sigaction(), либо выполнить системный вызов SignalAction() для их изменения будут приводить к ошибке EINVAL.
Кроме того, данные сигналы всегда маскированы и для них включена буферизация в очереди. Попытка их размаскирования с помощью функции sigprocmask() или системного вызова SignalProcmask() будет проигнорирована.
Обычный сигнал может быть сделан аналогичным "специальному" с помощью стандартных методов. Специальные сигналы избавляют программиста от необходимости писать схожий с указанным далее код и защищают себя от случайных изменений поведения.
sigset_t *set;struct sigaction action;sigemptyset( &set );sigaddset( &set, signo );sigprocmask( SIG_BLOCK, &set, NULL );action.sa_handler = SIG_DFL;action.sa_flags = SA_SIGINFO;sigaction( signo, &action, NULL );
Такая конфигурация делает сигналы подходящими для синхронного уведомления посредством функции sigwaitinfo() или системного вызова SignalWaitinfo(). Следующий пример кода блокируется до получения специального сигнала номер 8:
sigset_t *set;siginfo_t info;sigemptyset( &set );sigaddset( &set, SIGRTMAX + 8 );sigwaitinfo( &set, &info );printf( "Received signal %d with code %d and value %d\n",info.si_signo, info.si_code, info.si_value.sival_int );
Поскольку сигналы всегда замаскированы, программа не может быть прервана или терминирована в тех случаях, когда специальный сигнал получен вне функции sigwaitinfo(). Поскольку буферизация сигналов в очереди включена, они не будут потеряны — они будут поставлены в очередь до следующего вызова sigwaitinfo().
Специальные сигналы были разработаны для решения общей задачи межзадачного взаимодействия — необходимость сервера уведомить клиента о том, что он готов передать ему данные. Для этого сервер может использовать вызов MsgDeliverEvent(). Для передачи такого уведомления внутри события разумно использовать один из двух примитивов IPC: импульсы или сигналы.
Импульсы удобно применять для клиентов, которые также являются серверами в отношении своих собственных клиентов. В этом случае клиент может использовать единый канал для приема как уведомлений от сервера, так и сообщений/импульсов от своих клиентов.
Для большинства остальных клиентов дело обстоит иначе. Чтобы получить уведомление-импульс ему пришлось бы создать отдельный канал специально для этой цели и блокироваться на нем. В случае синхронных сигналов (т.е. от замаскирован) с включенной буферизацией в очереди, то он может использоваться в качестве уведомления без отдельного канала. В этом случае клиент для ожидания сигнала заменяет вызов MsgReceive() на sigwaitinfo().
Такой механизм обработки сигналов используется в оконной оболочке Photon для ожидания событий. Кроме того, он применяется функцией select() для ожидания операций ввода/вывода от множества серверов. Из восьми специальных сигналов первые два имеют специальные имена.
#define SIGSELECT (SIGRTMAX + 1)#define SIGPHOTON (SIGRTMAX + 2)
Приведем краткое описание сигналов.
SIGSTOP. Сигнал игнорируется, если процесс остановлен. ThreadCtl( _NTO_TCTL_IO, 0 );
Ctrl + C для текущего процесса в терминале. SIGSTOP. Этот сигнал не может быть перехвачен или проигнорирован.
В стандарте POSIX предусмотрены неблокирующие механизмы обмена сообщениями, именуемые очередями сообщений. Наряду с каналами, очереди сообщений являются именованными объектами, которые подразумевают независимое сосуществование читателей и писателей. Очередь сообщений действует на основе приоритетов, которыми обладает каждое сообщение, и имеет более сложную структуру, чем каналы, но тем самым позволяет приложениям иметь больший контроль над коммуникациями.
Для использования механизма очередей сообщений необходимо запустить соответствующий сервер очередей. В ЗОСРВ «Нейтрино» имеется две реализации соответствующего менеджера ресурсов:
|
В отличие от примитивов обмена сообщениями, очереди сообщений реализованы вне микроядра.
Очереди сообщений обеспечивают интерфейс, знакомый многим разработчикам приложений реального времени и во многом схожий с концепцией почтовых ящиков (англ. mailboxes).
Между сообщениями и очередями сообщений имеется фундаментальное различие. Сообщения являются блокирующими и основаны на прямом копировании данных между адресными пространствами процессов. Очереди сообщений же подразумевают промежуточное хранение на сервере, благодаря которому отправитель не блокируется и может отправлять сообщения в очередь асинхронно с получателем. Очереди существуют независимо от процессов, использующих их. Типовым сценарием применения является создание ряда именованных очередей для использования множеством процессов.
С точки зрения производительности, однако, очереди сообщений работают медленнее, чем непосредственный обмен сообщениями. Связано это в первую очередь с двойным копированием данных: от отправителя к серверу и от сервера к потребителю. Тем не менее, в ряде случаев предлагаемая процедурная гибкость механизма может компенсировать подобные издержки.
С точки зрения программного интерфейса очереди сообщений похожи на файлы. Она может быть открыта с помощью функции mq_open(), закрыта с помощью mq_close() и уничтожена через mq_unlink(). Передача сообщений (запись данных в менеджер ресурсов) может быть осуществлена с использованием функции mq_send(), а получение (чтение данных) через mq_receive().
Для строгого соответствия стандарту POSIX имена очередей сообщений должны начинаться с символа / (слэш) и не содержать других слэшей. Однако, в порядке ОС-специфичного расширения данное требование не является обязательным.
Рассмотрим реализацию очередей конкретнее. Все создаваемые очереди сообщений монтируются в пространство имен через каталог, зависимый от реализации сервера:
Примеры имен очередей, создаваемых с помощью функции mq_open(), и соответствующие им точки монтирования в пространстве имен (cwd — текущая рабочая директория):
| Имя очереди | Префикс (традиционная реализация) | Префикс (альтернативная реализация) |
|---|---|---|
/data | /dev/mqueue/data | /dev/mq/data |
/engine/data | /engine/data | /dev/mq/engine/data |
entry | cwd/entry | /dev/mq/cwd/entry |
entry/subentry | cwd/entry/subentry | /dev/mq/cwd/entry/subentry |
С помощью команды ls можно отобразить все очереди сообщений в системе, например:
# ls -Rl /dev/mqueue/ /dev/mqueue/: total 0 nrwxrwxr-x 1 root root 0 Dec 17 23:20 data dr-xr-xr-x 2 root root 0 Dec 17 23:20 engine /dev/mqueue/engine: total 1 nrwxrwxr-x 1 root root 1 Dec 17 23:20 data
| Размер, отображаемый при выполнении этой команды, означает количество ожидающих в очереди сообщений. |
Независимо от реализации сервера очередей, управление очередями сообщений выполняется с помощи следующих функций:
| Функция | Описание |
|---|---|
| mq_open() | Открытие очереди сообщений |
| mq_close() | Закрытие очереди сообщений |
| mq_unlink() | Удаление очереди сообщений |
| mq_send() | Добавление сообщения в очередь |
| mq_receive() | Извлечение сообщения из очереди |
| mq_notify() | Запрос на получение уведомления при поступлении сообщений в очередь |
| mq_setattr() | Установка атрибутов очереди |
| mq_getattr() | Чтение атрибутов очереди |
Разделяемая память (англ. shared memory) является механизмом межзадачного взаимодействия с максимальной производительностью. После создания некоторого объекта в разделяемой памяти все процессы, имеющие к нему доступ, могут обращаться по простому указателю для прямого доступа к данным. В тоже время это означает, что доступ к разделяемой памяти требует внешней синхронизации. Так, если один процесс обновляет её содержимое, другой процесс должен воздержаться от обращений. Даже в случае чтения результат может оказаться непредсказуемым.
Для решения этой проблемы разделяемая память часто используется в сочетании с одним из примитивов синхронизации или синхронным механизмом IPC. Однако, если гранулярность обновлений мала, то само использование примитивов синхронизации может сильно ограничить ее пропускную способность. Таким образом, наибольшая производительность разделяемой памяти достигается в том случае, когда блок единомоментно обновляемых данных имеет достаточно большой размер.
В качестве примитивов синхронизации для разделяемой памяти подходят как семафоры, так и мьютексы. В стандарте POSIX семафоры были определены как средство межпроцессной синхронизации, в то время как мьютексы — инструмент синхронизации потоков. Мьютексы могут также использоваться для синхронизации потоков в разных процессах, хотя POSIX считает это необязательным. В общем случае, мьютексы эффективнее, чем семафоры.
Сочетание разделяемой памяти с механизмом обмена сообщениями обеспечивает следующие возможности межзадачного взаимодействия:
С помощью механизма обмена сообщениями клиент отправляет запрос серверу и блокируется. Сервер обрабатывает сообщения клиентов в соответствии с их приоритетами и отправляет ответ, если может выполнить запрос. Сама операция передачи сообщения служит естественным механизмом синхронизации между клиентом и сервером. Вместо копирования данных при обмене сообщениями выгоднее передавать в сообщении ссылку разделяемую память. Благодаря ей сервер сможет модифицировать данные, оставаясь синхронным относительно клиента.
Разделяемая память не может использоваться процессами на разных узлах сети. Таким образом, сервер может использовать разделяемую память для локальных клиентов и обмен сообщениями для удаленных. Это позволяет получить высокопроизводительный сервер, который к тому же полагается на сетевую прозрачность.
Потоки одного процесса совместно используют память, доступную через его адресное пространство. Для совместного использования памяти разными процессами необходимо создать объект памяти, который будет отображен ( смапирован) в адресные пространства всех заинтересованных процессов. Для создания и управления такими объектами используются вызовы, перечисленные в таблице:
| Функция | Классификация | Описание |
|---|---|---|
| shm_open() | POSIX | Открытие или создание объекта разделяемой памяти |
| close() | POSIX | Закрытие объекта разделяемой памяти |
| mmap*() | POSIX | Мапирование области разделяемой памяти в адресное пространство текущего процесса |
| munmap() | POSIX | Освобождение смапированной области разделяемой памяти |
| munmap_flags() | ЗОСРВ «Нейтрино» | Освобождение смапированной область разделяемой памяти. Данная функция предоставляет больше возможностей, чем munmap() |
| mmap64_peer() | ЗОСРВ «Нейтрино» | Мапирование области разделяемой памяти в адресное пространство другого процесса |
| munmap_peer() | ЗОСРВ «Нейтрино» | Освобождение ранее смапированной в адресное пространство другого процесса области разделяемой памяти |
| mem_offset*() | ЗОСРВ «Нейтрино» | Получение смещения смапированного блока памяти |
| mem_offset64_peer() | ЗОСРВ «Нейтрино» | Получение информацию о смапированном блоке памяти в другом процессе |
| mprotect() | POSIX | Изменение атрибутов защиты для заданной области разделяемой памяти |
| msync() | POSIX | Синхронизация содержимого виртуальной памяти с физической памятью |
| shm_ctl(), shm_ctl_special() | ЗОСРВ «Нейтрино» | Назначение специальных атрибутов для объекта разделяемой памяти |
| shm_unlink() | POSIX | Удаление из системы объекта разделяемой памяти (активные мапирования этой памяти во всех процессах не изменяются) |
Разделяемая память стандарта POSIX реализуется в ЗОСРВ «Нейтрино» посредством менеджера процессов ( procnto). Перечисленные выше вызовы основываются на передаче ему сообщений (подробнее см. в статье Микроядро: менеджер процессов).
Функция shm_open() принимает такие же аргументы, что и функция open(), и возвращает объект файлового дескриптора. Эта функция позволяет как создавать новые, так и открывать существующие объекты разделяемой памяти.
Файловый дескриптор требуется открыть для чтения; для записи в объект разделяемой памяти также потребуется доступ по записи, если не задан параметр MAP_PRIVATE функции mmap(). |
При создании нового объекта разделяемой памяти его размер устанавливается равным нулю. Для изменения размера используется функция ftruncate() или функция shm_ctl().
Если объект разделяемой памяти создан и имеет файловый дескриптор, то с помощью функции mmap() он можно быть полностью или частично отображен (смапирован) в адресное пространство процесса. Системный вызов mmap() является ключевым инструментом управления памятью в ЗОСРВ «Нейтрино».
| Функция mmap() так же может использоваться для отображения файлов и типизированных объектов памяти на адресное пространство. |
Функция mmap() определена следующим образом:
void * mmap( void *addr,size_t length,int mem_protection,int mapping_flags,int fd,off_t offset );
В общем случае она выполняет следующее: отображение в адресное пространство текущего процесса length байт данных со смещением offset из объекта разделяемой памяти, связанного с дескриптором файла fd.
Микроядро будет стремиться смапировать содержимое памяти по виртуальному адресу addr, если данный параметр функции задан. Смапированная область памяти получит атрибуты защиты, заданные через параметр mem_protection, а отображение памяти будет выполнено с учетом флагов mapping_flags.
Аргументы fd, offset и length определяют параметры части объекта разделяемой памяти, которая будет отображена в адресное пространство. В большинстве случаев мапируется весь объект целиком. В этом случае offset задается равным 0, а length — равным размеру объекта в байтах. На процессорах Intel этот параметр определяется числом, кратным размеру страницы (по умолчанию 4096 байт).

При успешном завершении функция mmap() возвращает виртуальный адрес, по которому доступна разделяемая память. Аргумент addr позволяет указать системе куда именно в адресном пространстве следует поместить мапируемый объект, но только если это возможно. В большинстве случаев этот параметр устанавливают равным NULL, что позволяет менеджеру памяти микроядра самостоятельно определить будущий адрес отображаемого объекта.
В качестве параметра mem_protection может быть использована комбинация следующих флагов:
| Обратите внимание, что данный флаг является расширением ЗОСРВ «Нейтрино» и в большинстве случаев отсутствует в других POSIX-совместимых системах. |
Флаг PROT_NOCACHE используется в том числе и в тех случаях, когда память может быть изменена со стороны устройств периферии (например, видео буфер). Без этого процессор может оперировать устаревшими данными, которые остались в кеше и не были синхронизированы с физическим хранилищем (с уже изменённой физической памятью).
Флаги, задаваемые параметром mapping_flags, определяют способ отображения памяти. Эти флаги разбиваются на две группы. Первая определяет способ использования или тип памяти (может быть выбран только один из этих флагов):
Для разделения памяти между процессами используется MAP_SHARED, в то время, как MAP_PRIVATE имеет более специализированное применение.
В сочетании с выбранным типом памяти могут быть установлены (с помощью битовой операции ИЛИ) модификатор метода отображения. Рассмотрим нескольких наиболее интересных из этих флагов:
NOFD). Выделенная память будет занулена (см. параграф "Инициализация выделенной памяти" далее). MAP_PRIVATE. Использование вместе с MAP_SHARED подходит для процессов, основанных на вызове fork(). addr. Если область разделяемой памяти содержит указатели, то может потребоваться расположить ее по одному и тому же адресу во всех процессах. Альтернативой является использование смещения внутри области разделяемой памяти вместо указателей. NOFD. При использовании без флага MAP_ANON параметр offset задает точный физический адрес мапируемой памяти. В сочетании с MAP_ANON происходит выделение физически непрерывной области системной памяти (например, для DMA-буфера). MAP_NOX64K и MAP_BELOW16M служат для дальнейшего уточнения способа выделения MAP_ANON-памяти и ограничения диапазона разрешенных адресов, что требуется в некоторых формах DMA-операций. Вместо MAP_PHYS рекомендуется использовать mmap_device_memory(), за исключением случаев, когда требуется выделить блоки физически непрерывной памяти. |
| Обратите внимание, что данный флаг является расширением ЗОСРВ «Нейтрино» и в большинстве случаев отсутствует в других POSIX-совместимых системах. |
MAP_PHYS | MAP_ANON. Выделенная область памяти не будет превышать нижних 64 Кбайт физической памяти. Этот флаг необходим для старых 16-битных DMA-контроллеров. MAP_PHYS | MAP_ANON. Выделенная область памяти не будет превышать нижних 16 Мбайт физической памяти. Это требуется для работы DMA-контроллеров с устройствами на шине ISA.
| Полный перечень флагов, их назначение и особенности использования подробно описаны на странице с описанием функции mmap(). |
С помощью описанных здесь флагов процесс может достаточно легко управлять совместным использованием памяти с другими процессами:
/* Отображение области разделяемой памяти */fd = shm open( "datapoints", O_RDWR );addr = mmap( 0, len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0 );
Или выделять память, совместно используемую с оборудованием (например, графическим контроллером):
/* Отобразить видеопамять VGA */addr = mmap( 0, 65536, PROT_READ | PROT_WRITE, MAP_PHYS | MAP_SHARED, NOFD, 0xa0000 );
Также, можно выделить физически непрерывный DMA-буфер для устройства (например, для сетевой карты на шине PCI):
/* Выделить физически сплошной буфер */addr = mmap( 0, 262144, PROT_READ | PROT_WRITE | PROT_NOCACHE, MAP_PHYS | MAP_ANON, NOFD, 0 );
С помощью функции munmap() объект разделяемой памяти можно полностью или частично отмапировать (отсоединить) от адресного пространства. Применение этого системного вызова не ограничивается разделяемой памятью, он может также использоваться для освобождения любой области памяти в процессе. В сочетании с флагом MAP_ANON функция mmap() позволяет реализовать собственный механизм постраничного выделения/освобождения/переиспользования памяти.
| Не стоит использовать munmap() для освобождения памяти, выделенной с помощью функций вроде malloc(), поскольку такая память является буферизируемой в системной библиотеке. Нештатное ее освобождение не приведет к удалению ссылок на эти страницы во внутренних структурах системной библиотеки. |
С помощью функции mprotect() можно изменить атрибуты защиты области памяти. Функция munmap() также как и mprotect() не ограничивается разделяемой памяти и может применяться для изменения атрибутов любой области памяти в процессе.
По стандарту POSIX подразумевается, что mmap() обнуляет любую выделяемую память. Инициализация памяти может занять некоторое время, поэтому ЗОСРВ «Нейтрино» позволяет управлять этим требованием. Это увеличивает скорость, но может быть причиной проблем с безопасностью.
Отказ от инициализации памяти требует координации процессов мапирующих и освобождающих память:
int munmap_flags( void *addr, size_t len, unsigned flags );
Возможна передача следующих флагов в качестве парамера flags:
MAP_NOINIT в вызове mmap() и отображаемая физическая память ранее не освобождалась с флагом UNMAP_INIT_OPTIONAL, требование POSIX обнуления памяти не будет выполнено. По умолчанию ядро инициализирует память, но этим можно управлять с помощью опции -m для procnto. В качестве аргумента ей передается строка, позволяющая управлять поведением менеджера памяти:
Следует еще раз отметить, что вызов munmap_flags() с 0 в качестве параметра flags эквивалентен munmap().
Типизированная память — это часть дополнительной функциональности стандарта POSIX, являющаяся расширением реального времени и определенная в спецификации 1003.1. Функции, реализующие эти механизмы, объявлены в заголовочном файле <sys/mman.h>.
Типизированная память добавляет в системную библиотеку следующие функции:
POSIX-совместимая типизированная память предоставляет интерфейсы для открытия ОС-специфичных объектов и мапирования их. Эти механизмы полезны при обеспечении абстракции между BSP или устройство-специфичными ресурсами и драйверами устройств или прикладными программами.
POSIX определяет, что способ организации пулов объектов типизированной памяти зависит от конкретной реализации. Данный раздел описывает реализацию в ЗОСРВ «Нейтрино»:
В ЗОСРВ «Нейтрино» объекты типизированной памяти соответствуют регионам памяти, которые указаны в секции asinfo системной страницы. Таким образом, объекты типизированной памяти напрямую отображаются в иерархии адресного пространства (сегменты asinfo), определенные модулем startup. Такие объекты наследуют свойства, определённые в asinfo: физический адрес и границы сегментов памяти.
В общем случае именование и свойства элементов структуры asinfo является произвольными и полностью контролируется пользователем. Ряд элементов, однако, является обязательным:
Поскольку sysram является памятью, которой распоряжается менеджер памяти микроядра, то этот пул используется для удовлетворения анонимных запросов к mmap() и malloc().
Пользователь может создать дополнительные объекты типизированной памяти с помощью вызова функции as_add() в модуле startup.
Имена регионов типизированной памяти формируются из имён сегментов asinfo. Секция asinfo описывает иерархию, поэтому имена регионов типизированной памяти также являются иерархическими. Пример возможной конфигурации системы:
| Имя | Диапазон (начало, конец) |
|---|---|
/memory | 0, 0xFFFFFFFF |
/memory/ram | 0, 0x1FFFFFF |
/memory/ram/sysram | 0x1000, 0x1FFFFFF |
/memory/isa/ram/dma | 0x1000, 0xFFFFFF |
/memory/ram/dma | 0x1000, 0x1FFFFFF |
Имя, передаваемое функции posix_typed_mem_open(), следует представленному выше соглашению об именах. POSIX оставляет на усмотрение реализации поведение для случаев, когда имя не начинается с символа /. Рассмотрим правила разрешения имен при открытии типизированных объектов памяти:
/, выполняется поиск с точным совпадением.
/, которые рассматриваются как разделители компонентов пути. Если путь содержит несколько компонентов, сопоставление осуществляется снизу вверх (в противоположность разрешению имен файлов).
/, то оно рассматривается как суффикс искомого имени типизированного объекта. Используя приведенный выше пример конфигурации системы, рассмотрим несколько вариантов разрешения имен функцией posix_typed_mem_open():
| Запрашиваемое имя | Найденный объект | Соответствие правилам |
|---|---|---|
/memory | /memory | Правило 1 |
/memory/ram | /memory/ram | Правило 2 |
/sysram | Ошибка | — |
sysram | /memory/ram/sysram | Правило 3 |
Иерархия имен объектов типизированной памяти отображается на пространство имен менеджера процессов через каталог /dev/tymem. Для получения информации о типизированной памяти приложения могут просматривать как иерархию, так и записи секции asinfo в системной странице.
| В отличие от объектов разделяемой памяти, открыть типизированную память через пространство имен нельзя, поскольку функция posix_typed_mem_open() принимает дополнительный параметр tflag, который обязателен и не обслуживается функцией open() системной библиотеки. |
Для типизированной памяти предлагаются следующие общие случаи аллоцирования и мапирования в адресное пространство процесса:
POSIX_TYPED_MEM_ALLOCATE и POSIX_TYPED_MEM_ALLOCATE_CONTIG функции posix_typed_mem_open()). Этот случай похож на обычный MAP_SHARED для анонимного объекта:
mmap( 0, 0x1000, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANON, NOFD, 0 );
Выделенная память будет недоступной для других процессов, за исключением дочерних процессов. Она будет освобождена при удалении последней ссылки на нее (при явном освобождении памяти или завершении процесса).
Обратите внимание, что если кто-либо получает доступ к ранее выделенному объекту, выполнив mem_offset() и затем MAP_PHYS, аналогичным путем кто-либо другой может открыть объект типизированной памяти с флагом POSIX_TYPED_MEMORY_ALLOCATABLE (или без флагов) и получить доступ к той же физической памяти.
Флаг POSIX_TYPED_MEM_ALLOC_CONTIG подобен комбинации MAP_ANON | MAP_SHARED в том смысле, что обеспечивается выделение непрерывного блока памяти.
POSIX_TYPED_MEM_MAP_ALLOCATABLE функции posix_typed_mem_open() используется для мапирования объекта без выделения. Это аналогично разделяемого отображения физической памяти. Следует использовать только режим MAP_SHARED, поскольку запись в режиме MAP_PRIVATE будет (как правило) создавать в обычной анонимной памяти приватную копию данных для данного процесса.
Если флаги функции posix_typed_mem_open() не заданы или задан POSIX_TYPED_MEM_MAP_ALLOCATABLE, то параметр offset функции mmap() задает начальный физический адрес в объекте типизированной памяти. При этом, если объект типизированной памяти не является непрерывным (несколько элементов asinfo), то допускаются не последовательные не начинающиеся с нуля значения offset, как это делается для объектов разделяемой памяти. Если задается регион [paddr, paddr + size), который выходит за пределы границ объекта типизированной памяти, то функция mmap() завершится неуспешно с кодом ошибки ENXIO.
Доступ к объекту типизированной памяти управляется стандартными правами доступа в UNIX-подобных системах (т.е. согласно дискреционному принципу разграничения прав доступа). Желаемый режим доступа задается с помощью аргумента oflags функции posix_typed_mem_open(), который проверяется на соответствие маске прав доступа данного объекта.
POSIX не определяет способ назначения атрибутов доступа объектам типизированной памяти. В ЗОСРВ «Нейтрино» атрибуты доступа по умолчанию определяются в момент загрузки системы. По умолчанию владельцем и группой является root, который имеет право на чтение и запись, а все остальные пользователи не имеют никаких прав доступа к ресурсу.
В настоящее время не существует механизма изменения права доступа к объекту в процессе исполнения системы.
Размер объекта можно узнать с помощью функции posix_typed_mem_get_info(). Она заполняет структуру posix_typed_mem_info, которая включает поле posix_tmi_length, содержащее размер объекта типизированной памяти.
Согласно стандарту POSIX, данное поле является динамическим и содержит лишь текущий размер объекта, доступный для выделения. По сути это размер свободного пространства в объекте для режимов POSIX_TYPED_MEM_ALLOCATE и POSIX_TYPED_MEM_ALLOCATE_CONTIG. Если объект открыт с tflag равным 0 или POSIX_TYPED_MEM_MAP_ALLOCATABLE, то поле posix_tmi_length будет равно 0.
При мапировании в адресное пространство процесса объекта типизированной памяти в функцию mmap() обычно передается смещение offset. Оно характеризует начальный физический адрес в объекте, с которого должно начинаться отображение в память. Задавать смещение уместно только при открытии объекта с tflag равным 0 или POSIX_TYPED_MEM_MAP_ALLOCATABLE. Если же объект открыт с POSIX_TYPED_MEM_ALLOCATE или POSIX_TYPED_MEM_ALLOCATE_CONTIG, то ненулевое смещение приведет к ошибке вызова mmap() с кодом EINVAL.
RLIMIT_VMEM или RLIMIT_AS. RLIMIT_DATA.
Рассмотрим ряд примеров использования объектов типизированной памяти.
int fd = posix_typed_mem_open( "/memory/ram/sysram", O_RDWR,POSIX_TYPED_MEM_ALLOCATE_CONTIG );...unsigned vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,MAP_PRIVATE, fd, 0 );
Допустим, что имеется некоторая специальная память (например, быстрая SRAM), которую необходимо использовать как пакетную память. Ресурсы SRAM не входит в глобальный пул системной памяти. Вместо этого в модуле startup может использоваться функция as_add() для добавления элемента asinfo в системную страницу:
as_add( phys_addr, phys_addr + size - 1, AS_ATTR_NONE, "packet_memory", mem_id );
где phys_addr — физический адрес SRAM, size — ее размер, а mem_id — идентификатор (ID) родителя (обычно это память, возвращаемая функцией as_default()). Этот код создает элемент asinfo с именем "packet_memory", который затем может быть использован как объект типизированной памяти.
Следующий код может использоваться различными приложениями для выделения страницы памяти из объекта с именем "packet_memory":
int fd = posix_typed_mem_open( "packet_memory", O_RDWR,POSIX_TYPED_MEM_ALLOCATE );...unsigned vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,MAP_SHARED, fd, 0 );
В качестве альтернативы можно использовать пакетную память как общий физический буфер. В этом случае приложения могут использовать его следующим образом:
int fd = posix_typed_mem_open( "packet_memory", O_RDWR,POSIX_TYPED_MEM_MAP_ALLOCATABLE );...unsigned vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,MAP_SHARED, fd, offset );
В некоторых системах из-за аппаратных ограничений выполнение DMA-операции (операции прямого доступа к памяти) с произвольными адресами может оказаться невозможным. В некоторых случаях чипсет разрешает DMA-операции лишь для некоторого подмножества физической памяти. В общем случае доступ к такой памяти сложно организовать без предварительного статического резервирования памяти с заданными характеристиками для дальнейшего использования драйверами. Потенциально это является расточительным, поскольку исключает из регулярного использования всех указанных диапазонов памяти (так как точный объем потребностей драйверов в памяти установить сложно). Типизированная память предоставляет четкий механизм для решения такого рода проблем, не требующий резервирований больших блоков памяти.
Рассмотрим пример. В модуле startup с помощью as_add_containing() создается запись asinfo для DMA-безопасной памяти. Такая запись должна являться потомком объекта с именем "ram":
as_add_containing( dma_addr, dma_addr + size - 1, AS_ATTR_RAM, "dma", "ram" );
где dma_addr — физический адрес начала фрагмента ОЗУ, безопасного для DMA-операций, а size — размер этого фрагмента (региона). Этот код создает элемент asinfo с именем "dma", являющийся потомком объекта с именем "ram".
Драйверы могут следующим образом использовать этот объект типизированной памяти для выделения DMA-безопасных буферов:
int fd = posix_typed_mem_open( "ram/dma", O_RDWR,POSIX_TYPED_MEM_ALLOCATE_CONTIG );...unsigned vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,MAP_SHARED, fd, 0 );
Для использования неименованных (англ. pipe) и именованных (англ. FIFO) каналов необходимо, чтобы был запущен менеджер ресурсов pipe.
Pipe — это безымянный файл, который служит в качестве однонаправленного канала ввода/вывода между несколькими взаимодействующими процессами: один процесс записывает данные в канал, другой процесс читает из него. Менеджер ресурсов pipe при этом выполняет промежуточную буферизацию данных. Размер буфера определяется через PIPE_BUF в заголовочном файле <limits.h>. Канал уничтожается после закрытия всех участвующих в обмене процессов (читателя и писателя). Функция pathconf() позволяет получить размер буфера.
Каналы обычно используются для организации параллельной работы двух процессов. При этом данные передаются по каналу от одного процесса другому только в одном направлении и по мере их поступления. Если передача данных должна быть двунаправленной, следует использовать обмен сообщениями.
Типичный способ применения неименованных каналов — соединение выхода одной программы со входом другой. Такое соединение часто устанавливается с помощью командного интерпретатора. Пример:
ls | more
В результате выполнения этой операции выходные данные утилиты ls будут направлены по каналу на вход утилиты more.
Варианты использования:
|).
FIFO аналогичны неименованным каналам, кроме того, что они представляют собой именованные постоянные файлы, которые представлены в каталогах файловой системы.
Варианты использования:
Предыдущий раздел: перейти